Note
This is the legacy documentation (v1). For the latest version, please visit the current documentation.This section contains the original documentation that is being migrated to a new structure.
This is the multi-page printable view of this section. Click here to print.
This section contains the original documentation that is being migrated to a new structure.
The challenge of IPCEI-CIS Developer Framework is to provide value for DTAG customers, and more specifically: for Developers of DTAG customers.
That’s why we need verifications - or test use cases - for the Developer Framework to develop.
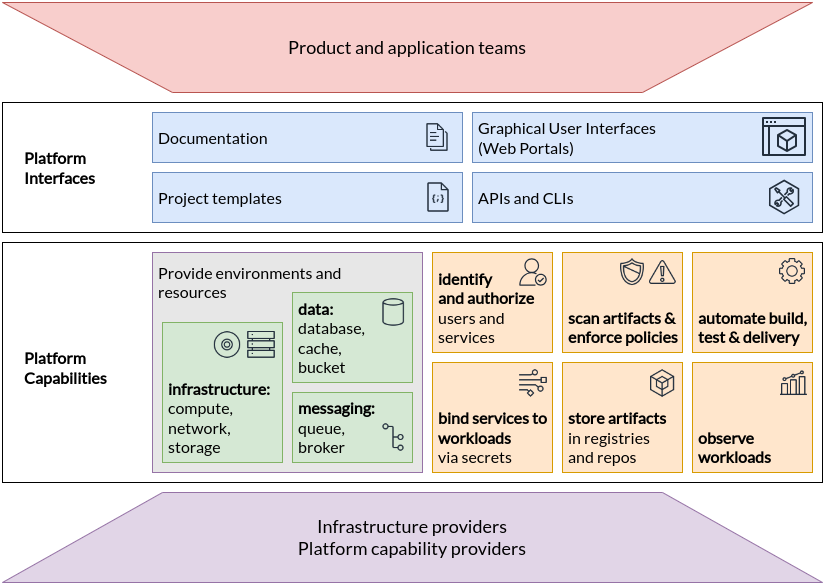 (source: https://tag-app-delivery.cncf.io/whitepapers/platforms/)
(source: https://tag-app-delivery.cncf.io/whitepapers/platforms/)
Here we have a collection of possible usage scenarios.
Deploy and develop the famous socks shops:
See also mkdev fork: https://github.com/mkdev-me/microservices-demo
The Fibonacci App on the cluster can be accessed on the path https://cnoe.localtest.me/fibonacci. It can be called for example by using the URL https://cnoe.localtest.me/fibonacci?number=5000000.
The resulting ressource spike can be observed one the Grafana dashboard “Kubernetes / Compute Resources / Cluster”. The resulting visualization should look similar like this:

…. taken from https://cloud.google.com/blog/products/application-development/common-myths-about-platform-engineering?hl=en
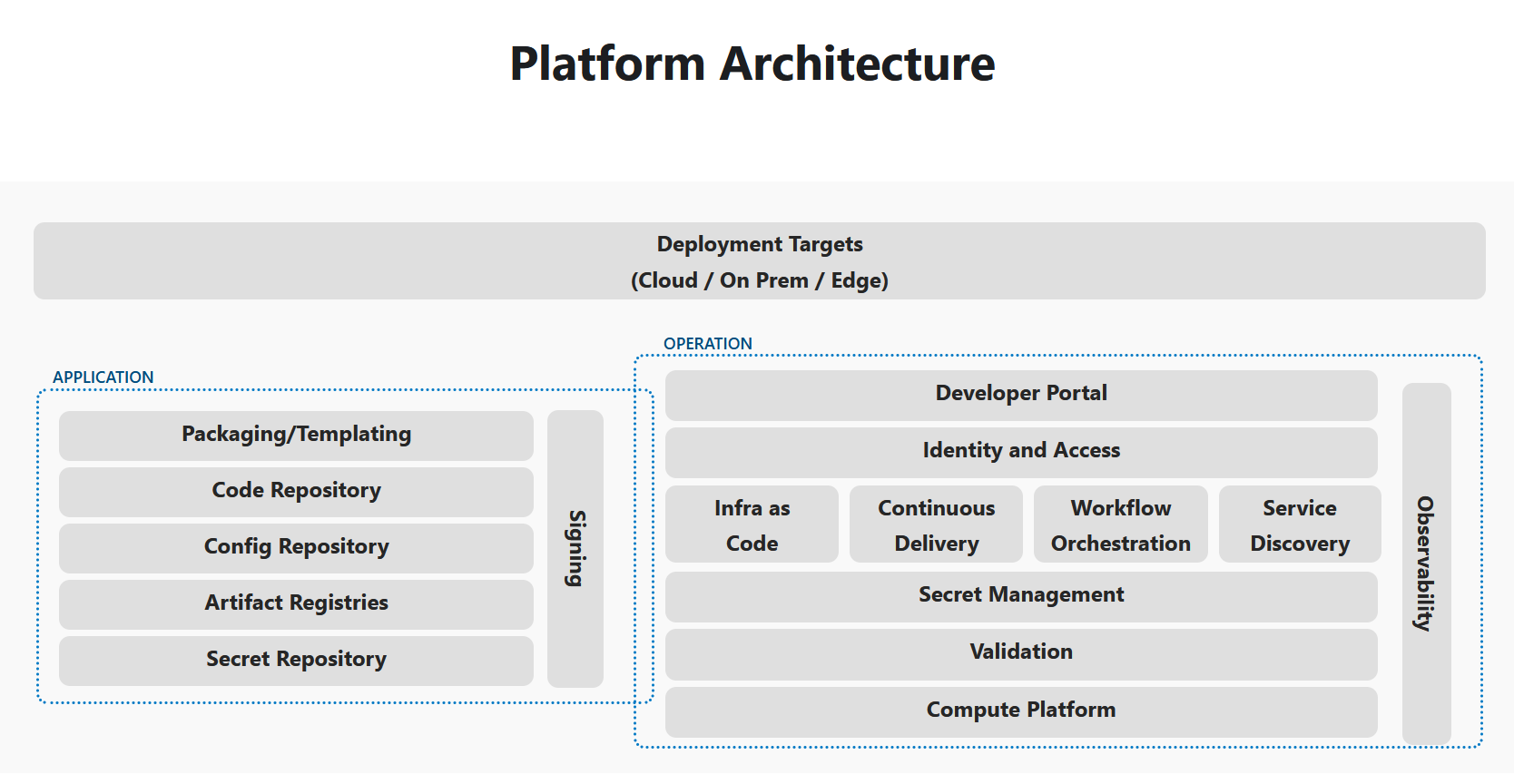
IPCEI-CIS Developer Framework is part of a cloud native technology stack. To design the capabilities and architecture of the Developer Framework we need to define the surounding context and internal building blocks, both aligned with cutting edge cloud native methodologies and research results.
In CNCF the discipline of building stacks to enhance the developer experience is called ‘Platform Engineering’
CNCF first asks why we need platform engineering:
The desire to refocus delivery teams on their core focus and reduce duplication of effort across the organisation has motivated enterprises to implement platforms for cloud-native computing. By investing in platforms, enterprises can:
- Reduce the cognitive load on product teams and thereby accelerate product development and delivery
- Improve reliability and resiliency of products relying on platform capabilities by dedicating experts to configure and manage them
- Accelerate product development and delivery by reusing and sharing platform tools and knowledge across many teams in an enterprise
- Reduce risk of security, regulatory and functional issues in products and services by governing platform capabilities and the users, tools and processes surrounding them
- Enable cost-effective and productive use of services from public clouds and other managed offerings by enabling delegation of implementations to those providers while maintaining control over user experience
platformengineering.org’s Definition of Platform EngineeringPlatform engineering is the discipline of designing and building toolchains and workflows that enable self-service capabilities for software engineering organizations in the cloud-native era. Platform engineers provide an integrated product most often referred to as an “Internal Developer Platform” covering the operational necessities of the entire lifecycle of an application.
https://humanitec.com/blog/wtf-internal-developer-platform-vs-internal-developer-portal-vs-paas
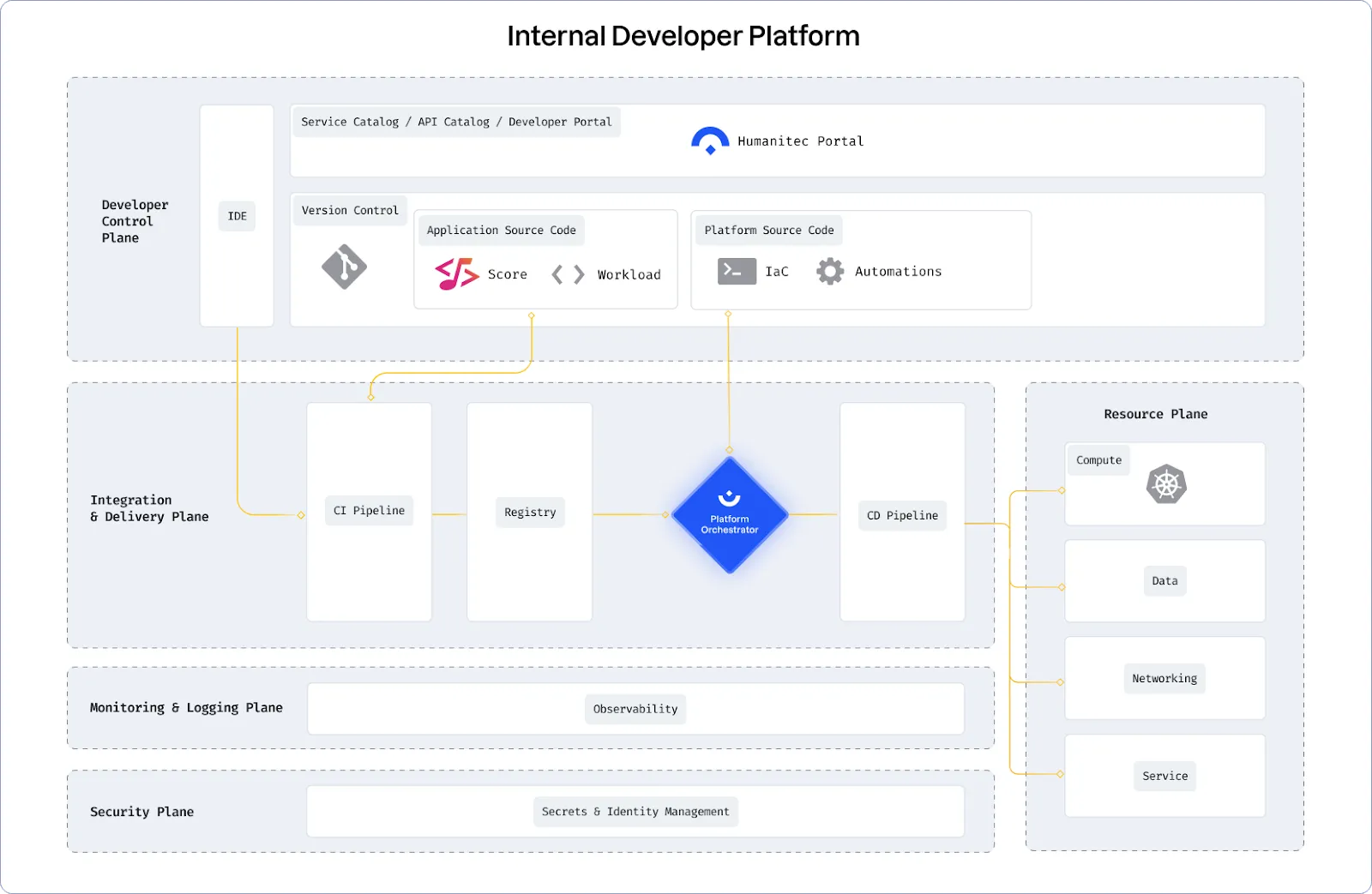
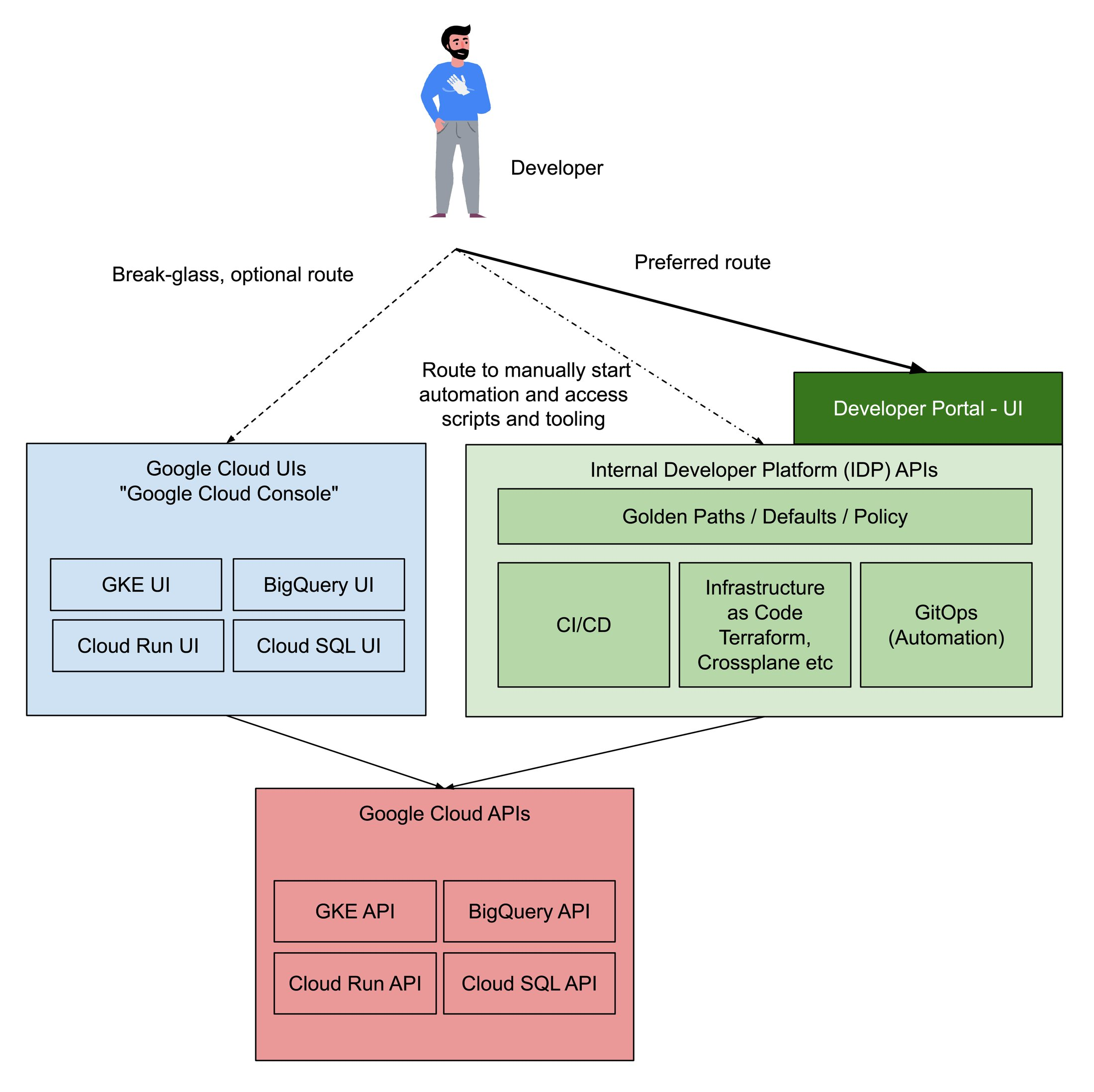
In IPCEI-CIS right now (July 2024) we are primarily interested in understanding how IDPs are built as one option to implement an IDP is to build it ourselves.
The outcome of the Platform Engineering discipline is - created by the platform engineering team - a so called ‘Internal Developer Platform’.
One of the first sites focusing on this discipline was internaldeveloperplatform.org
The amount of available IDPs as product is rapidly growing.
[TODO] LIST OF IDPs
Cortex is talking about Use Cases (aka Initiatives): (or https://www.brighttalk.com/webcast/20257/601901)
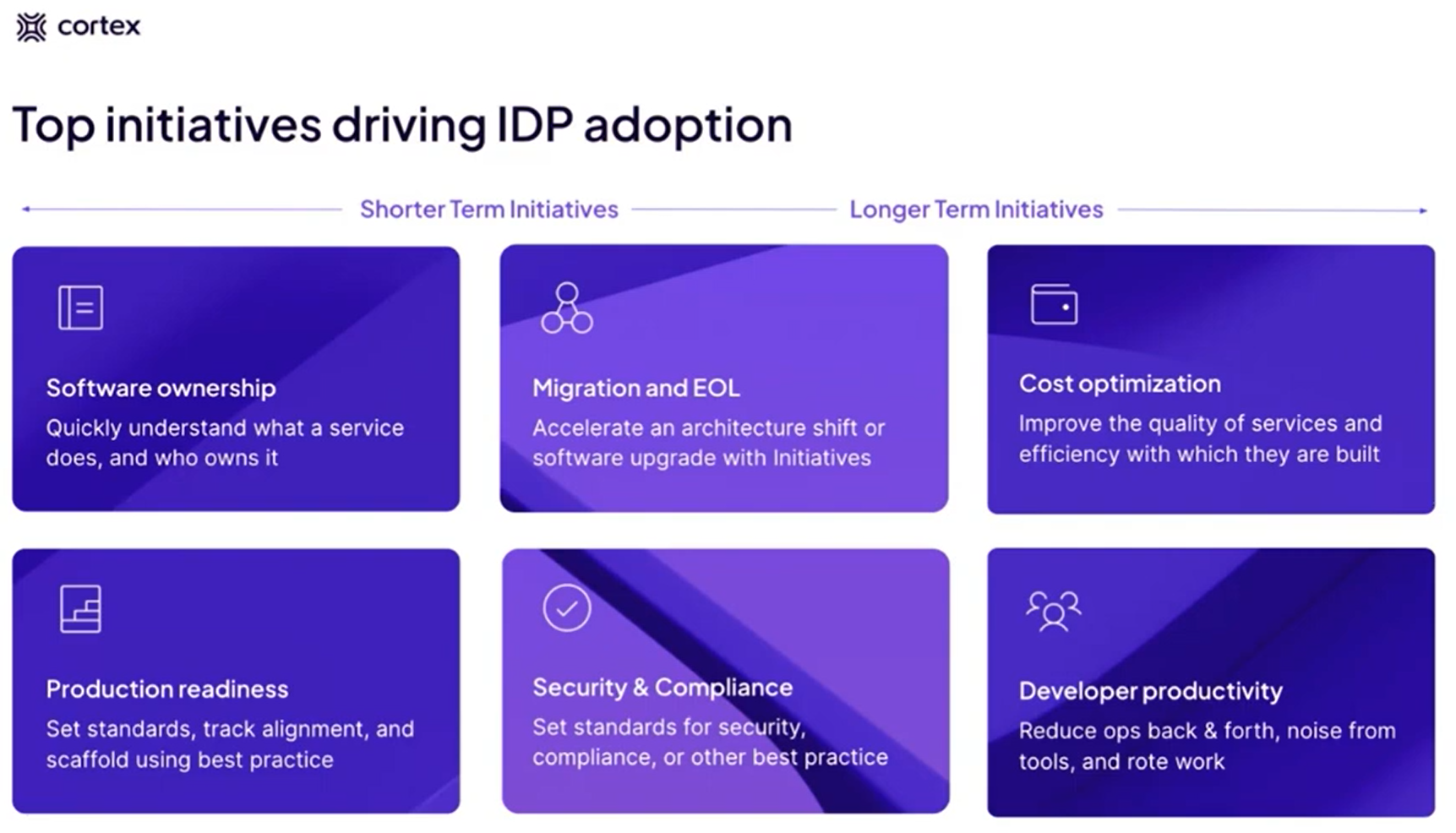
In a platform reference architecture there are five main planes that make up an IDP:

(source: https://humanitec.com/blog/wtf-internal-developer-platform-vs-internal-developer-portal-vs-paas)
https://github.com/humanitec-architecture
https://humanitec.com/reference-architectures
This page is in work. Right now we have in the index a collection of links describing and listing typical components and building blocks of platforms. Also we have a growing number of subsections regarding special types of components.
See also:
This document describes the concept of pipelining in the context of the Edge Developer Framework.
In order to provide a composable pipeline as part of the Edge Developer Framework (EDF), we have defined a set of concepts that can be used to create pipelines for different usage scenarios. These concepts are:
Pipeline Contexts define the context in which a pipeline execution is run. Typically, a context corresponds to a specific step within the software development lifecycle, such as building and testing code, deploying and testing code in staging environments, or releasing code. Contexts define which components are used, in which order, and the environment in which they are executed.
Components are the building blocks, which are used in the pipeline. They define specific steps that are executed in a pipeline such as compiling code, running tests, or deploying an application.
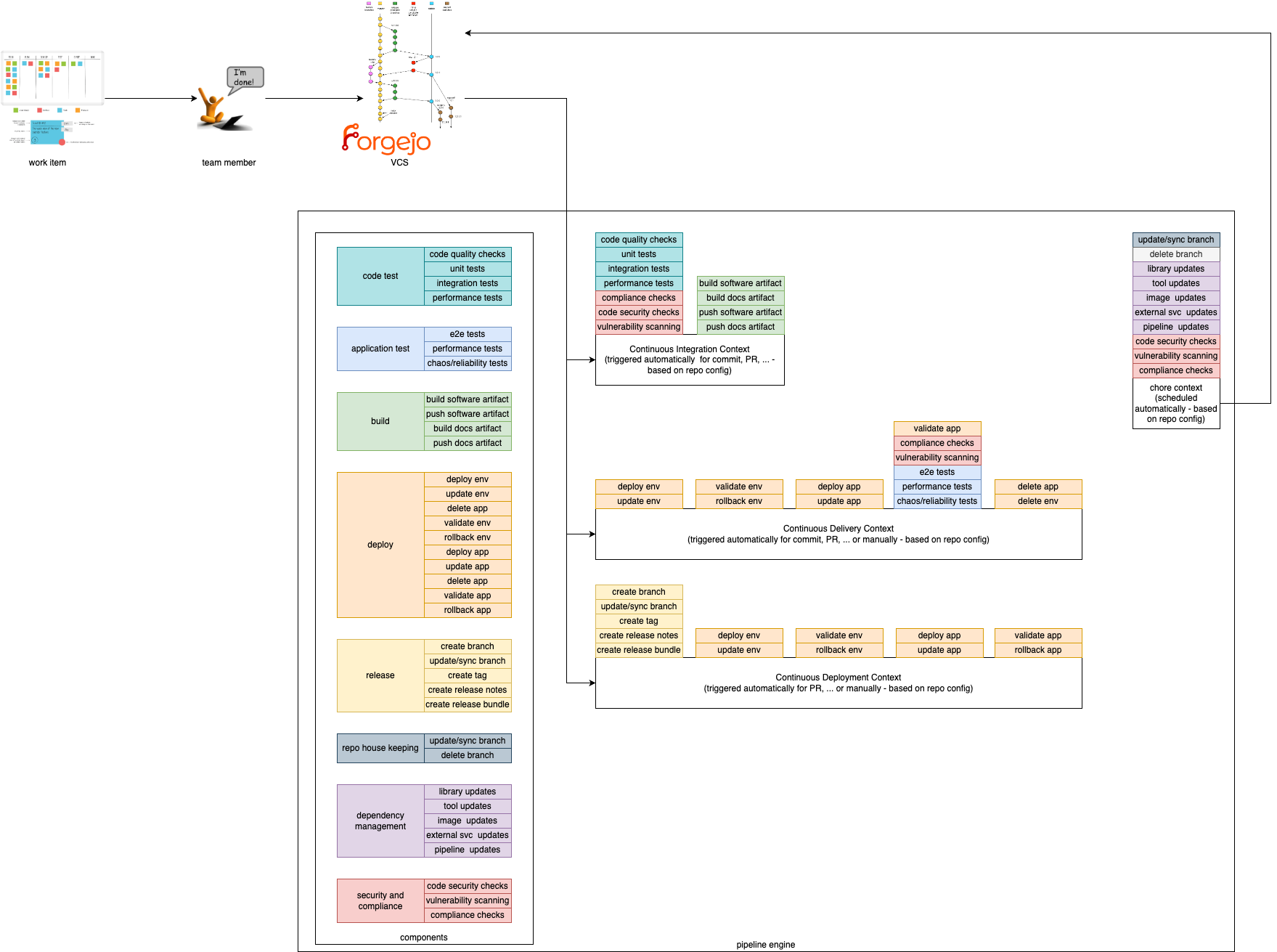
We provide 4 Pipeline Contexts that can be used to create pipelines for different usage scenarios. The contexts can be described as the golden path, which is fully configurable and extenable by the users.
Pipeline runs with a given context can be triggered by different actions. For example, a pipeline run with the Continuous Integration context can be triggered by a commit to a repository, while a pipeline run with the Continuous Delivery context could be triggered by merging a pull request to a specific branch.
This context is focused on running tests and checks on every commit to a repository. It is used to ensure that the codebase is always in a working state and that new changes do not break existing functionality. Tests within this context are typically fast and lightweight, and are used to catch simple errors such as syntax errors, typos, and basic logic errors. Static vulnerability and compliance checks can also be performed in this context.
This context is focused on deploying code to a (ephermal) staging environment after its static checks have been performed. It is used to ensure that the codebase is always deployable and that new changes can be easily reviewed by stakeholders. Tests within this context are typically more comprehensive than those in the Continuous Integration context, and handle more complex scenarios such as integration tests and end-to-end tests. Additionally, live security and compliance checks can be performed in this context.
This context is focused on deploying code to a production environment and/or publishing artefacts after static checks have been performed.
This context focuses on measures that need to be carried out regularly (e.g. security or compliance scans). They are used to ensure the robustness, security and efficiency of software projects. They enable teams to maintain high standards of quality and reliability while minimizing risks and allowing developers to focus on more critical and creative aspects of development, increasing overall productivity and satisfaction.
Components are the composable and self-contained building blocks for the contexts described above. The aim is to cover most (common) use cases for application teams and make them particularly easy to use by following our golden paths. This way, application teams only have to include and configure the functionalities they actually need. An additional benefit is that this allows for easy extensibility. If a desired functionality has not been implemented as a component, application teams can simply add their own.
Components must be as small as possible and follow the same concepts of software development and deployment as any other software product. In particular, they must have the following characteristics:
In the EDF components are divided into different categories. Each category contains components that perform similar actions. For example, the build category contains components that compile code, while the deploy category contains components that automate the management of the artefacts created in a production-like system.
Note: Components are comparable to interfaces in programming. Each component defines a certain behaviour, but the actual implementation of these actions depends on the specific codebase and environment.
For example, the
buildcomponent defines the action of compiling code, but the actual build process depends on the programming language and build tools used in the project. Thevulnerability scanningcomponent will likely execute different tools and interact with different APIs depending on the context in which it is executed.
Build components are used to compile code. They can be used to compile code written in different programming languages, and can be used to compile code for different platforms.
These components define tests that are run on the codebase. They are used to ensure that the codebase is always in a working state and that new changes do not break existing functionality. Tests within this category are typically fast and lightweight, and are used to catch simple errors such as syntax errors, typos, and basic logic errors. Tests must be executable in isolation, and do not require external dependencies such as databases or network connections.
Application tests are tests, which run the code in a real execution environment, and provide external dependencies. These tests are typically more comprehensive than those in the Code Test category, and handle more complex scenarios such as integration tests and end-to-end tests.
Deploy components are used to deploy code to different environments, but can also be used to publish artifacts. They are typically used in the Continuous Delivery and Continuous Deployment contexts.
Release components are used to create releases of the codebase. They can be used to create tags in the repository, create release notes, or perform other tasks related to releasing code. They are typically used in the Continuous Deployment context.
Repo house keeping components are used to manage the repository. They can be used to clean up old branches, update the repository’s README file, or perform other maintenance tasks. They can also be used to handle issues, such as automatically closing stale issues.
Dependency management is used to automate the process of managing dependencies in a codebase. It can be used to create pull requests with updated dependencies, or to automatically update dependencies in a codebase.
Security and compliance components are used to ensure that the codebase meets security and compliance requirements. They can be used to scan the codebase for vulnerabilities, check for compliance with coding standards, or perform other security and compliance checks. Depending on the context, different tools can be used to accomplish scanning. In the Continuous Integration context, static code analysis can be used to scan the codebase for vulnerabilities, while in the Continuous Delivery context, live security and compliance checks can be performed.
We have Gitops these days …. so there is a desired state of an environment in a repo and a reconciling mechanism done by Gitops to enforce this state on the environemnt.
There is no continuous whatever step inbetween … Gitops is just ‘overwriting’ (to avoid saying ‘delivering’ or ‘deploying’) the environment with the new state.
This means whatever quality ensuring steps have to take part before ‘overwriting’ have to be defined as state changer in the repos, not in the environments.
Conclusio: I think we only have three contexts, or let’s say we don’t have the contect ‘continuous delivery’
This page is in work. Right now we have in the index a collection of links describing developer portals.
https://www.getport.io/compare/backstage-vs-port
‘Platform Orchestration’ is first mentionned by Thoughtworks in Sept 2023
Here are capability domains to consider when building platforms for cloud-native computing:
An Internal Developer Platform (IDP) should be built to cover 5 Core Components:
| Core Component | Short Description |
|---|---|
| Application Configuration Management | Manage application configuration in a dynamic, scalable and reliable way. |
| Infrastructure Orchestration | Orchestrate your infrastructure in a dynamic and intelligent way depending on the context. |
| Environment Management | Enable developers to create new and fully provisioned environments whenever needed. |
| Deployment Management | Implement a delivery pipeline for Continuous Delivery or even Continuous Deployment (CD). |
| Role-Based Access Control | Manage who can do what in a scalable way. |
The goal for the CNOE framework is to bring together a cohort of enterprises operating at the same scale so that they can navigate their operational technology decisions together, de-risk their tooling bets, coordinate contribution, and offer guidance to large enterprises on which CNCF technologies to use together to achieve the best cloud efficiencies.
See https://cnoe.io/docs/reference-implementation/integrations/reference-impl:
# in a local terminal with docker and kind
idpbuilder create --use-path-routing --log-level debug --package-dir https://github.com/cnoe-io/stacks//ref-implementation
time=2024-08-05T14:48:33.348+02:00 level=INFO msg="Creating kind cluster" logger=setup
time=2024-08-05T14:48:33.371+02:00 level=INFO msg="Runtime detected" logger=setup provider=docker
########################### Our kind config ############################
# Kind kubernetes release images https://github.com/kubernetes-sigs/kind/releases
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
image: "kindest/node:v1.29.2"
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "ingress-ready=true"
extraPortMappings:
- containerPort: 443
hostPort: 8443
protocol: TCP
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."gitea.cnoe.localtest.me:8443"]
endpoint = ["https://gitea.cnoe.localtest.me"]
[plugins."io.containerd.grpc.v1.cri".registry.configs."gitea.cnoe.localtest.me".tls]
insecure_skip_verify = true
######################### config end ############################
time=2024-08-05T14:48:33.394+02:00 level=INFO msg="Creating kind cluster" logger=setup cluster=localdev
time=2024-08-05T14:48:53.680+02:00 level=INFO msg="Done creating cluster" logger=setup cluster=localdev
time=2024-08-05T14:48:53.905+02:00 level=DEBUG+3 msg="Getting Kube config" logger=setup
time=2024-08-05T14:48:53.908+02:00 level=DEBUG+3 msg="Getting Kube client" logger=setup
time=2024-08-05T14:48:53.908+02:00 level=INFO msg="Adding CRDs to the cluster" logger=setup
time=2024-08-05T14:48:53.948+02:00 level=DEBUG+3 msg="crd not yet established, waiting." "crd name"=custompackages.idpbuilder.cnoe.io
time=2024-08-05T14:48:53.954+02:00 level=DEBUG+3 msg="crd not yet established, waiting." "crd name"=custompackages.idpbuilder.cnoe.io
time=2024-08-05T14:48:53.957+02:00 level=DEBUG+3 msg="crd not yet established, waiting." "crd name"=custompackages.idpbuilder.cnoe.io
time=2024-08-05T14:48:53.981+02:00 level=DEBUG+3 msg="crd not yet established, waiting." "crd name"=gitrepositories.idpbuilder.cnoe.io
time=2024-08-05T14:48:53.985+02:00 level=DEBUG+3 msg="crd not yet established, waiting." "crd name"=gitrepositories.idpbuilder.cnoe.io
time=2024-08-05T14:48:54.734+02:00 level=DEBUG+3 msg="Creating controller manager" logger=setup
time=2024-08-05T14:48:54.737+02:00 level=DEBUG+3 msg="Created temp directory for cloning repositories" logger=setup dir=/tmp/idpbuilder-localdev-2865684949
time=2024-08-05T14:48:54.737+02:00 level=INFO msg="Setting up CoreDNS" logger=setup
time=2024-08-05T14:48:54.798+02:00 level=INFO msg="Setting up TLS certificate" logger=setup
time=2024-08-05T14:48:54.811+02:00 level=DEBUG+3 msg="Creating/getting certificate" logger=setup host=cnoe.localtest.me sans="[cnoe.localtest.me *.cnoe.localtest.me]"
time=2024-08-05T14:48:54.825+02:00 level=DEBUG+3 msg="Creating secret for certificate" logger=setup host=cnoe.localtest.me
time=2024-08-05T14:48:54.832+02:00 level=DEBUG+3 msg="Running controllers" logger=setup
time=2024-08-05T14:48:54.833+02:00 level=DEBUG+3 msg="starting manager"
time=2024-08-05T14:48:54.833+02:00 level=INFO msg="Creating localbuild resource" logger=setup
time=2024-08-05T14:48:54.834+02:00 level=INFO msg="Starting EventSource" controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage source="kind source: *v1alpha1.CustomPackage"
time=2024-08-05T14:48:54.834+02:00 level=INFO msg="Starting EventSource" controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository source="kind source: *v1alpha1.GitRepository"
time=2024-08-05T14:48:54.834+02:00 level=INFO msg="Starting Controller" controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage
time=2024-08-05T14:48:54.834+02:00 level=INFO msg="Starting Controller" controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository
time=2024-08-05T14:48:54.834+02:00 level=INFO msg="Starting EventSource" controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild source="kind source: *v1alpha1.Localbuild"
time=2024-08-05T14:48:54.834+02:00 level=INFO msg="Starting Controller" controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild
time=2024-08-05T14:48:54.937+02:00 level=INFO msg="Starting workers" controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository "worker count"=1
time=2024-08-05T14:48:54.937+02:00 level=INFO msg="Starting workers" controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage "worker count"=1
time=2024-08-05T14:48:54.937+02:00 level=INFO msg="Starting workers" controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild "worker count"=1
time=2024-08-05T14:48:56.863+02:00 level=DEBUG+3 msg=Reconciling controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild Localbuild.name=localdev namespace="" name=localdev reconcileID=cc0e5b9d-4952-4fd1-9d62-6d9821f180be resource=/localdev
time=2024-08-05T14:48:56.863+02:00 level=DEBUG+3 msg="Create or update namespace" controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild Localbuild.name=localdev namespace="" name=localdev reconcileID=cc0e5b9d-4952-4fd1-9d62-6d9821f180be resource="&Namespace{ObjectMeta:{idpbuilder-localdev 0 0001-01-01 00:00:00 +0000 UTC <nil> <nil> map[] map[] [] [] []},Spec:NamespaceSpec{Finalizers:[],},Status:NamespaceStatus{Phase:,Conditions:[]NamespaceCondition{},},}"
time=2024-08-05T14:48:56.983+02:00 level=DEBUG+3 msg="installing core packages" controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild Localbuild.name=localdev namespace="" name=localdev reconcileID=cc0e5b9d-4952-4fd1-9d62-6d9821f180be
time=2024-08-05T14:
...
time=2024-08-05T14:51:04.166+02:00 level=INFO msg="Stopping and waiting for webhooks"
time=2024-08-05T14:51:04.166+02:00 level=INFO msg="Stopping and waiting for HTTP servers"
time=2024-08-05T14:51:04.166+02:00 level=INFO msg="Wait completed, proceeding to shutdown the manager"
########################### Finished Creating IDP Successfully! ############################
Can Access ArgoCD at https://cnoe.localtest.me:8443/argocd
Username: admin
Password can be retrieved by running: idpbuilder get secrets -p argocd
Nach ca. 10 minuten sind alle applications ausgerollt (am längsten dauert Backstage):
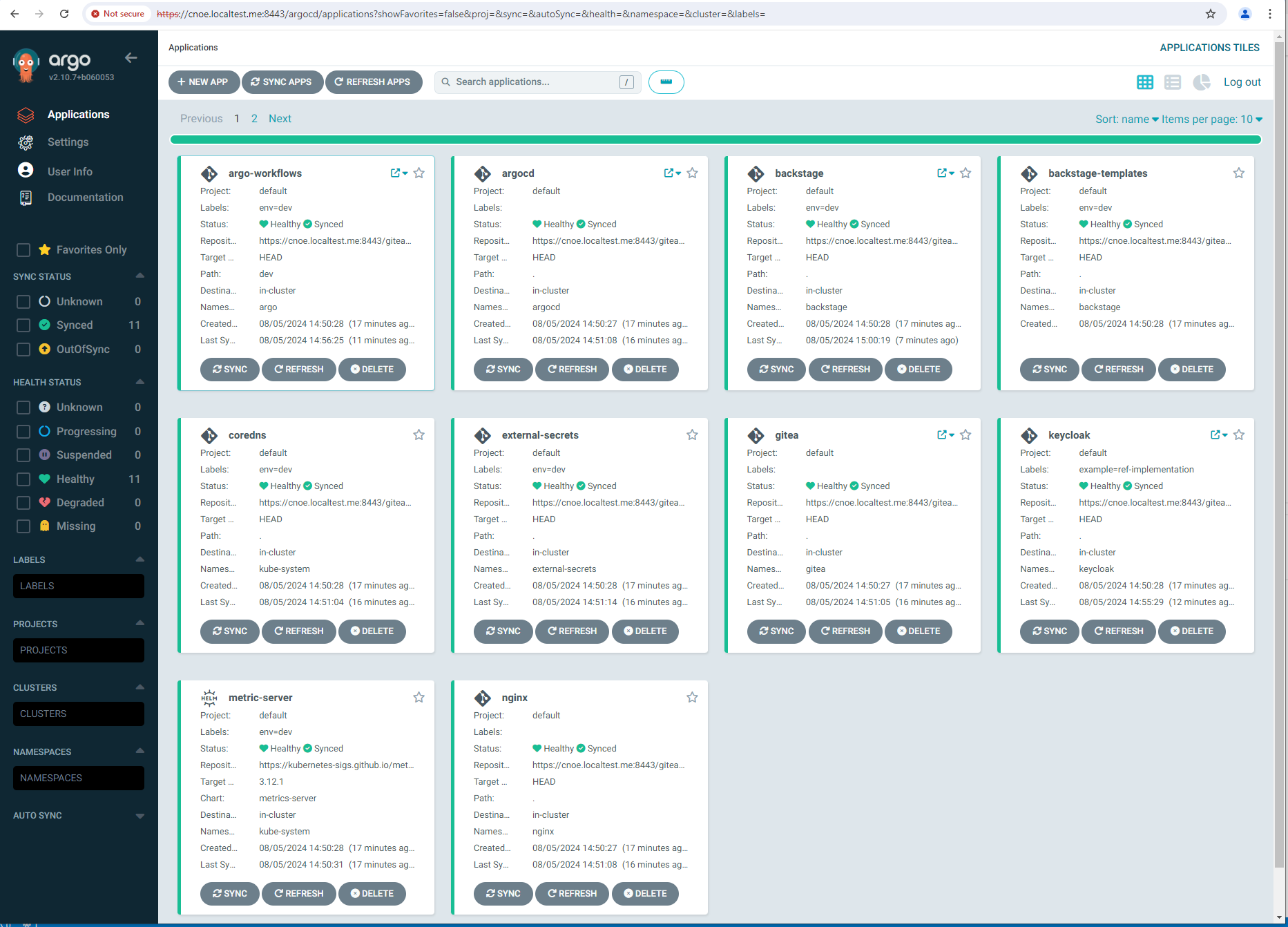
stl@ubuntu-vpn:~$ kubectl get applications -A
NAMESPACE NAME SYNC STATUS HEALTH STATUS
argocd argo-workflows Synced Healthy
argocd argocd Synced Healthy
argocd backstage Synced Healthy
argocd included-backstage-templates Synced Healthy
argocd coredns Synced Healthy
argocd external-secrets Synced Healthy
argocd gitea Synced Healthy
argocd keycloak Synced Healthy
argocd metric-server Synced Healthy
argocd nginx Synced Healthy
argocd spark-operator Synced Healthy
stl@ubuntu-vpn:~$ idpbuilder get secrets
---------------------------
Name: argocd-initial-admin-secret
Namespace: argocd
Data:
password : sPMdWiy0y0jhhveW
username : admin
---------------------------
Name: gitea-credential
Namespace: gitea
Data:
password : |iJ+8gG,(Jj?cc*G>%(i'OA7@(9ya3xTNLB{9k'G
username : giteaAdmin
---------------------------
Name: keycloak-config
Namespace: keycloak
Data:
KC_DB_PASSWORD : ES-rOE6MXs09r+fAdXJOvaZJ5I-+nZ+hj7zF
KC_DB_USERNAME : keycloak
KEYCLOAK_ADMIN_PASSWORD : BBeMUUK1CdmhKWxZxDDa1c5A+/Z-dE/7UD4/
POSTGRES_DB : keycloak
POSTGRES_PASSWORD : ES-rOE6MXs09r+fAdXJOvaZJ5I-+nZ+hj7zF
POSTGRES_USER : keycloak
USER_PASSWORD : RwCHPvPVMu+fQM4L6W/q-Wq79MMP+3CN-Jeo
login geht mit den Creds, siehe oben:
tbd
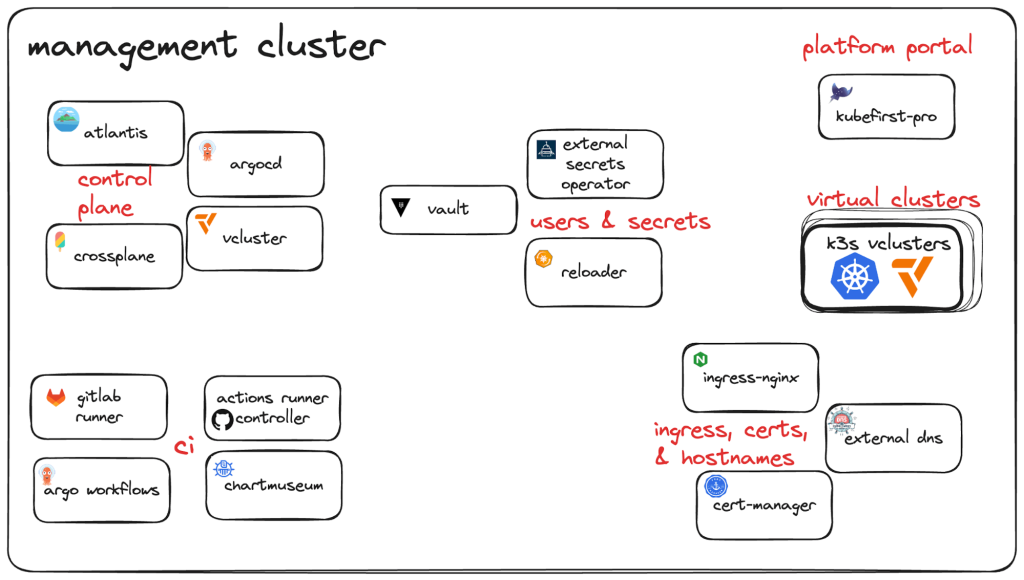
This design documentation structure is inspired by the design of crossplane.
EDF is running as a controlplane - or let’s say an orchestration plane, correct wording is still to be defined - in a kubernetes cluster. Right now we have at least ArgoCD as controller of manifests which we provide as CNOE stacks of packages and standalone packages.
The implementation of EDF must be kubernetes provider agnostic. Thus each provider specific deployment dependency must be factored out into provider specific definitions or deployment procedures.
This implies that EDF must always be deployable into a local cluster, whereby by ’local’ we mean a cluster which is under the full control of the platform engineer, e.g. a kind cluster on their laptop.
When booting and reconciling the ‘final’ stack exectuting orchestrator (here: ArgoCD) needs to get rendered (or hydrated) presentations of the manifests.
It is not possible or unwanted that the orchestrator itself resolves dependencies or configuration values.
The hydration takes place for all target clouds/kubernetes providers. There is no ‘default’ or ‘special’ setup, like the Kind version.
This implies that in a development process there needs to be a build step hydrating the ArgoCD manifests for the targeted cloud.
Discussion from Robert and Stephan-Pierre in the context of stack development - there should be an easy way to have locally changed stacks propagated into the local running platform.
tbd
==== 1 =====
There is a core eDF which is self-contained and does not have any impelmented dependency to external platforms. eDF depends on abstractions. Each embdding into customer infrastructure works with adapters which implement the abstraction.
==== 2 =====
eDF has an own IAM. This may either hold the principals and permissions itself when there is no other IAM or proxy and map them when integrated into external enterprise IAMs.
Arch call from 4.12.24, Florian, Stefan, Stephan-Pierre
TN: Robert, Patrick, Stefan, Stephan 25.2.25, 13-14h
we need charts, because:
(*): marker: “jetzt hab’ ich das erste mal so halbwegs verstanden was ihr da überhaupt macht” (**) marker: ????
Sebastiano, Stefan, Robert, Patrick, Stephan 25.2.25, 14-15h
edp standalone ipcei edp
produktstruktur application model (cnoe, oam, score, xrd, …) api backstage (usage scenarios) pipelining ’everything as code’, deklaratives deployment, crossplane (bzw. orchestrator)
ggf: identity mgmt
nicht: security monitoring kubernetes internals
pipelining kubernetes-inetrnals api crossplane platforming - erzeugen von ressourcen in ‘clouds’ (e.g. gcp, und hetzner :-) )
security identity-mgmt (SSI) EaC und alles andere macht mir auch total spass!
Robert worked on the kindserver reconciling.
He got aware that crossplane is able to delete clusters when drift is detected. This mustnt happen for sure in productive clusters.
Even worse, if crossplane did delete the cluster and then set it up again correctly, argocd would be out of sync and had no idea by default how to relate the old and new cluster.
* edgeXR erlaubt keine persistenz
* openai, llm als abstarktion nicht vorhanden
* momentan nur compute vorhanden
* roaming von applikationen --> EDP muss das unterstützen
* anwendungsfall: sprachmodell übersetzt design-artifakte in architektur, dann wird provisionierung ermöglicht
? Applikations-modelle ? zusammenhang mit golden paths * zB für reines compute faas
WiP - this is in work.
What kind of Gitops do we have with idpbuilder/CNOE ?
https://github.com/gitops-bridge-dev/gitops-bridge
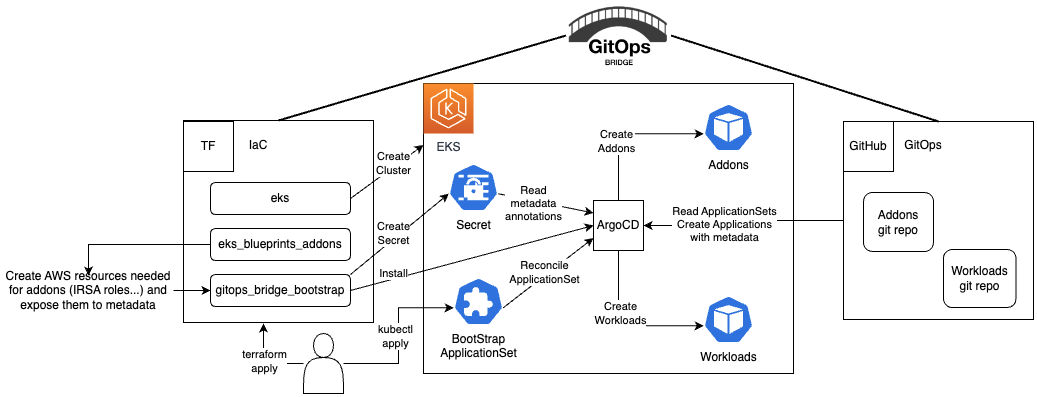
WiP - this is in work.
What deployment scenarios do we have with idpbuilder/CNOE ?
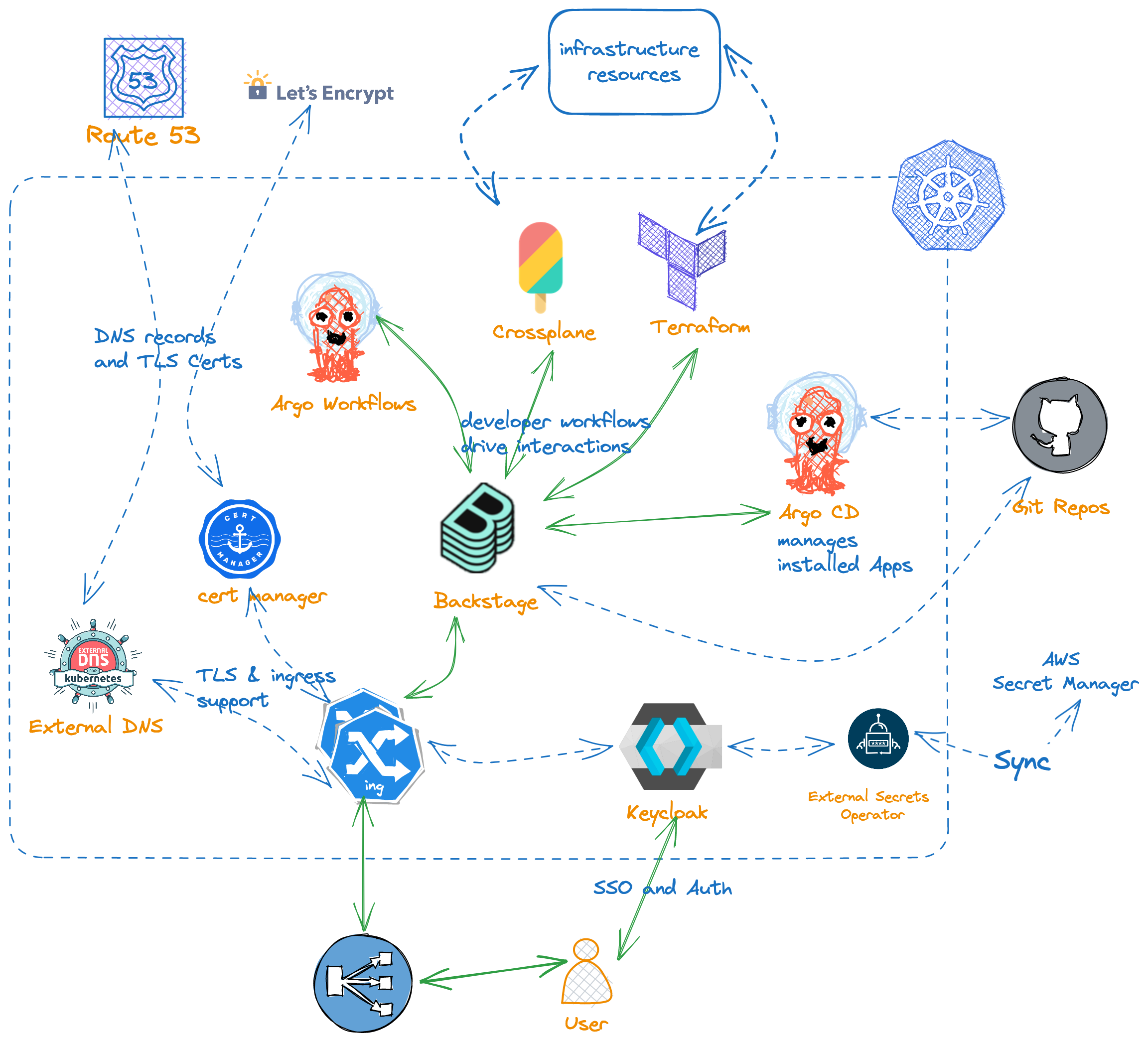
The next chart shows a system landscape of CNOE orchestration.
2024-04-PlatformEngineering-DevOpsDayRaleigh.pdf
Questions: What are the degrees of freedom in this chart? What variations with respect to environments and environmnent types exist?
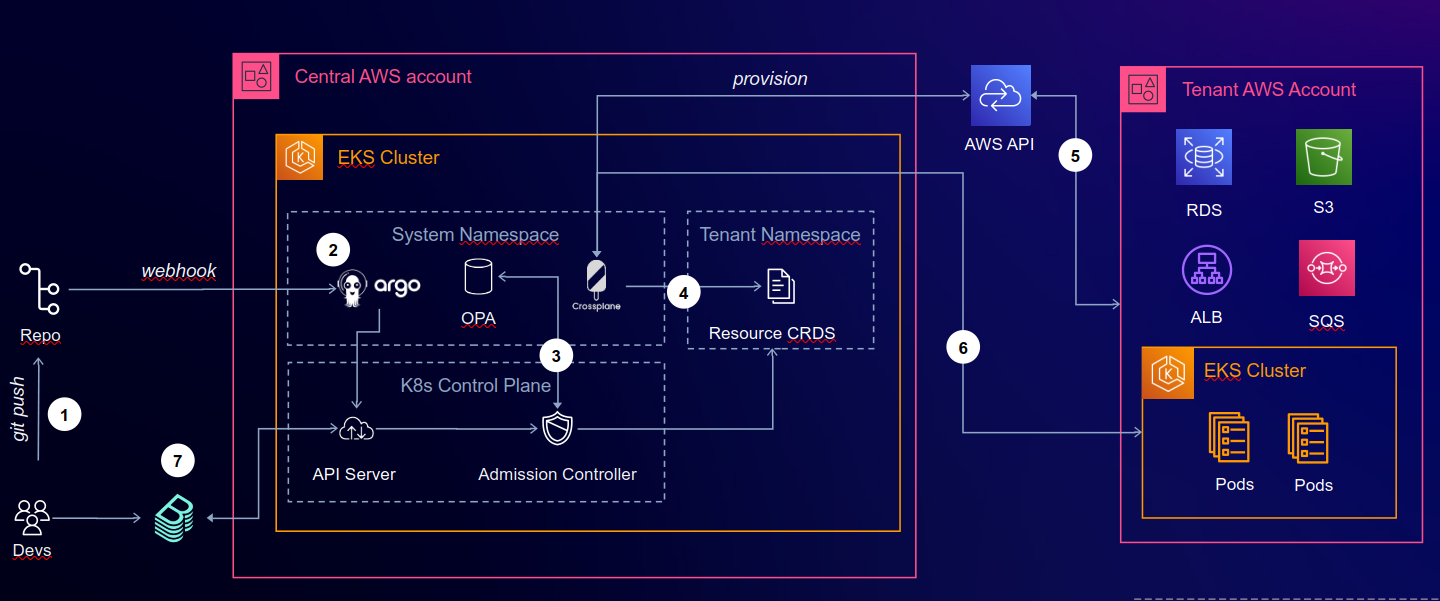
The next chart shows a context chart of CNOE orchestration.
Questions: What are the degrees of freedom in this chart? What variations with respect to environments and environmnent types exist?
Backstage by Spotify can be seen as a Platform Portal. It is an open platform for building and managing internal developer tools, providing a unified interface for accessing various tools and resources within an organization.
Key Features of Backstage as a Platform Portal: Tool Integration:
Backstage allows for the integration of various tools used in the development process, such as CI/CD, version control systems, monitoring, and others, into a single interface. Service Management:
It offers the ability to register and manage services and microservices, as well as monitor their status and performance. Documentation and Learning Materials:
Backstage includes capabilities for storing and organizing documentation, making it easier for developers to access information. Golden Paths:
Backstage supports the concept of “Golden Paths,” enabling teams to follow recommended practices for development and tool usage. Modularity and Extensibility:
The platform allows for the creation of plugins, enabling users to customize and extend Backstage’s functionality to fit their organization’s needs. Backstage provides developers with centralized and convenient access to essential tools and resources, making it an effective solution for supporting Platform Engineering and developing an internal platform portal.
This document provides a comprehensive guide on the prerequisites and the process to set up and run Backstage locally on your machine.
Before you start, make sure you have the following installed on your machine:
Node.js: Backstage requires Node.js. You can download it from the Node.js website. It is recommended to use the LTS version.
Yarn: Backstage uses Yarn as its package manager. You can install it globally using npm:
npm install --global yarn
Git
Docker
To install the Backstage Standalone app, you can use npx. npx is a tool that comes preinstalled with Node.js and lets you run commands straight from npm or other registries.
npx @backstage/create-app@latest
This command will create a new directory with a Backstage app inside. The wizard will ask you for the name of the app. This name will be created as sub directory in your current working directory.
Below is a simplified layout of the files and folders generated when creating an app.
app
├── app-config.yaml
├── catalog-info.yaml
├── package.json
└── packages
├── app
└── backend
You can run it in Backstage root directory by executing this command:
yarn dev
Catalog:
Docs:
API Docs:
TechDocs:
Scaffolder:
CI/CD:
Metrics:
Snyk:
SonarQube:
GitHub:
Backstage plugins and functionality extensions should be writen in TypeScript/Node.js because backstage is written in those languages
Create the Plugin
To create a plugin in the project structure, you need to run the following command at the root of Backstage:
yarn new --select plugin
The wizard will ask you for the plugin ID, which will be its name. After that, a template for the plugin will be automatically created in the directory plugins/{plugin id}. After this install all needed dependencies. After this install required dependencies. In example case this is "axios" for API requests
Emaple:
yarn add axios
Define the Plugin’s Functionality
In the newly created plugin directory, focus on defining the plugin’s core functionality. This is where you will create components that handle the logic and user interface (UI) of the plugin. Place these components in the plugins/{plugin_id}/src/components/ folder, and if your plugin interacts with external data or APIs, manage those interactions within these components.
Set Up Routes
In the main configuration file of your plugin (typically plugins/{plugin_id}/src/routs.ts), set up the routes. Use createRouteRef() to define route references, and link them to the appropriate components in your plugins/{plugin_id}/src/components/ folder. Each route will determine which component renders for specific parts of the plugin.
Register the Plugin
Navigate to the packages/app folder and import your plugin into the main application. Register your plugin in the routs array within packages/app/src/App.tsx to integrate it into the Backstage system. It will create a rout for your’s plugin page
Add Plugin to the Sidebar Menu
To make the plugin accessible through the Backstage sidebar, modify the sidebar component in packages/app/src/components/Root.tsx. Add a new sidebar item linked to your plugin’s route reference, allowing users to easily access the plugin through the menu.
Test the Plugin
Run the Backstage development server using yarn dev and navigate to your plugin’s route via the sidebar or directly through its URL. Ensure that the plugin’s functionality works as expected.
All steps will be demonstrated using a simple example plugin, which will request JSON files from the API of jsonplaceholder.typicode.com and display them on a page.
Creating test-plugin:
yarn new --select plugin
Adding required dependencies. In this case only “axios” is needed for API requests
yarn add axios
Implement code of the plugin component in plugins/{plugin-id}/src/{Component name}/{filename}.tsx
import React, { useState } from 'react';
import axios from 'axios';
import { Typography, Grid } from '@material-ui/core';
import {
InfoCard,
Header,
Page,
Content,
ContentHeader,
SupportButton,
} from '@backstage/core-components';
export const TestComponent = () => {
const [posts, setPosts] = useState<any[]>([]);
const [loading, setLoading] = useState(false);
const [error, setError] = useState<string | null>(null);
const fetchPosts = async () => {
setLoading(true);
setError(null);
try {
const response = await axios.get('https://jsonplaceholder.typicode.com/posts');
setPosts(response.data);
} catch (err) {
setError('Ошибка при получении постов');
} finally {
setLoading(false);
}
};
return (
<Page themeId="tool">
<Header title="Welcome to the Test Plugin!" subtitle="This is a subtitle">
<SupportButton>A description of your plugin goes here.</SupportButton>
</Header>
<Content>
<ContentHeader title="Posts Section">
<SupportButton>
Click to load posts from the API.
</SupportButton>
</ContentHeader>
<Grid container spacing={3} direction="column">
<Grid item>
<InfoCard title="Information Card">
<Typography variant="body1">
This card contains information about the posts fetched from the API.
</Typography>
{loading && <Typography>Загрузка...</Typography>}
{error && <Typography color="error">{error}</Typography>}
{!loading && !posts.length && (
<button onClick={fetchPosts}>Request Posts</button>
)}
</InfoCard>
</Grid>
<Grid item>
{posts.length > 0 && (
<InfoCard title="Fetched Posts">
<ul>
{posts.map(post => (
<li key={post.id}>
<Typography variant="h6">{post.title}</Typography>
<Typography>{post.body}</Typography>
</li>
))}
</ul>
</InfoCard>
)}
</Grid>
</Grid>
</Content>
</Page>
);
};
Setup routs in plugins/{plugin_id}/src/routs.ts
import { createRouteRef } from '@backstage/core-plugin-api';
export const rootRouteRef = createRouteRef({
id: 'test-plugin',
});
packages/app/src/App.tsx in routes
Import of the plugin:import { TestPluginPage } from '@internal/backstage-plugin-test-plugin';
Adding route:
const routes = (
<FlatRoutes>
... //{Other Routs}
<Route path="/test-plugin" element={<TestPluginPage />} />
</FlatRoutes>
)
packages/app/src/components/Root/Root.tsx. This should be added in to Root object as another SidebarItemexport const Root = ({ children }: PropsWithChildren<{}>) => (
<SidebarPage>
<Sidebar>
... //{Other sidebar items}
<SidebarItem icon={ExtensionIcon} to="/test-plugin" text="Test Plugin" />
</Sidebar>
{children}
</SidebarPage>
);
yarn dev


Kratix is a Kubernetes-native framework that helps platform engineering teams automate the provisioning and management of infrastructure and services through custom-defined abstractions called Promises. It allows teams to extend Kubernetes functionality and provide resources in a self-service manner to developers, streamlining the delivery and management of workloads across environments.
Key concepts of Kratix:
Resource provisioning automation. Kratix simplifies infrastructure creation for developers through the abstraction of “Promises.” This means developers can simply request the necessary resources (like databases, message queues) without dealing with the intricacies of infrastructure management.
Flexibility and adaptability. Platform teams can customize and adapt Kratix to specific needs by creating custom Promises for various services, allowing the infrastructure to meet the specific requirements of the organization.
Unified resource request interface. Developers can use a single API (Kubernetes) to request resources, simplifying interaction with infrastructure and reducing complexity when working with different tools and systems.
Although Kratix offers great flexibility, it can also lead to more complex setup and platform management processes. Creating custom Promises and configuring their behavior requires time and effort.
Kubernetes dependency. Kratix relies on Kubernetes, which makes it less applicable in environments that don’t use Kubernetes or containerization technologies. It might also lead to integration challenges if an organization uses other solutions.
Limited ecosystem. Kratix doesn’t have as mature an ecosystem as some other infrastructure management solutions (e.g., Terraform, Pulumi). This may limit the availability of ready-made solutions and tools, increasing the amount of manual work when implementing Kratix.
Humanitec is an Internal Developer Platform (IDP) that helps platform engineering teams automate the provisioning and management of infrastructure and services through dynamic configuration and environment management.
It allows teams to extend their infrastructure capabilities and provide resources in a self-service manner to developers, streamlining the deployment and management of workloads across various environments.
Key concepts of Humanitec:
Application Definition:
This is an abstraction where developers define their application, including its services, environments, a dependencies. It abstracts away infrastructure details, allowing developers to focus on building and deploying their applications.
Dynamic Configuration Management:
Humanitec automatically manages the configuration of applications and services across multiple environments (e.g., development, staging, production). It ensures consistency and alignment of configurations as applications move through different stages of deployment.
Humanitec simplifies the development and delivery process by providing self-service deployment options while maintaining centralized governance and control for platform teams.
Resource provisioning automation. Humanitec automates infrastructure and environment provisioning, allowing developers to focus on building and deploying applications without worrying about manual configuration.
Dynamic environment management. Humanitec manages application configurations across different environments, ensuring consistency and reducing manual configuration errors.
Golden Paths. best-practice workflows and processes that guide developers through infrastructure provisioning and application deployment. This ensures consistency and reduces cognitive load by providing a set of recommended practices.
Unified resource management interface. Developers can use Humanitec’s interface to request resources and deploy applications, reducing complexity and improving the development workflow.
Humanitec is commercially licensed software
Integration challenges. Humanitec’s dependency on specific cloud-native environments can create challenges for organizations with diverse infrastructures or those using legacy systems.
Cost. Depending on usage, Humanitec might introduce additional costs related to the implementation of an Internal Developer Platform, especially for smaller teams.
Harder to customise
This Backstage template YAML automates the creation of an Argo Workflow for Kubernetes that includes a basic Spark job, providing a convenient way to configure and deploy workflows involving data processing or machine learning jobs. Users can define key parameters, such as the application name and the path to the main Spark application file. The template creates necessary Kubernetes resources, publishes the application code to a Gitea Git repository, registers the application in the Backstage catalog, and deploys it via ArgoCD for easy CI/CD management.
This template is designed for teams that need a streamlined approach to deploy and manage data processing or machine learning jobs using Spark within an Argo Workflow environment. It simplifies the deployment process and integrates the application with a CI/CD pipeline. The template performs the following:
This template boosts productivity by automating steps required for setting up Argo Workflows and Spark jobs, integrating version control, and enabling centralized management and visibility, making it ideal for projects requiring efficient deployment and scalable data processing solutions.
This Backstage template YAML automates the creation of a basic Kubernetes Deployment, aimed at simplifying the deployment and management of applications in Kubernetes for the user. The template allows users to define essential parameters, such as the application’s name, and then creates and configures the Kubernetes resources, publishes the application code to a Gitea Git repository, and registers the application in the Backstage catalog for tracking and management.
The template is designed for teams needing a streamlined approach to deploy applications in Kubernetes while automatically configuring their CI/CD pipelines. It performs the following:
This template enhances productivity by automating several steps required for deployment, version control, and registration, making it ideal for projects where fast, consistent deployment and centralized management are required.
The idpbuilder uses KIND as Kubernetes cluster. It is suggested to use a virtual machine for the installation. MMS Linux clients are unable to execute KIND natively on the local machine because of network problems. Pods for example can’t connect to the internet.
Windows and Mac users already utilize a virtual machine for the Docker Linux environment.
For building idpbuilder the source code needs to be downloaded and compiled:
git clone https://github.com/cnoe-io/idpbuilder.git
cd idpbuilder
go build
The idpbuilder binary will be created in the current directory.
To start the idpbuilder binary execute the following command:
./idpbuilder create --use-path-routing --log-level debug --package https://github.com/cnoe-io/stacks//ref-implementation
At the end of the idpbuilder execution a link of the installed ArgoCD is shown. The credentianls for access can be obtained by executing:
./idpbuilder get secrets
A Kubernetes config is created in the default location $HOME/.kube/config. A management of the Kubernetes config is recommended to not unintentionally delete acces to other clusters like the OSC.
To show all running KIND nodes execute:
kubectl get nodes -o wide
To see all running pods:
kubectl get pods -o wide
Follow this documentation: https://github.com/cnoe-io/stacks/tree/main/ref-implementation
The cluster can be deleted by executing:
idpbuilder delete cluster
CNOE provides two implementations of an IDP:
Both are not useable to run on bare metal or an OSC instance. The Amazon implementation is complex and makes use of Terraform which is currently not supported by either base metal or OSC. Therefore the KIND implementation is used and customized to support the idpbuilder installation. The idpbuilder is also doing some network magic which needs to be replicated.
Several prerequisites have to be provided to support the idpbuilder on bare metal or the OSC:
Talos Linux is choosen for a bare metal Kubernetes instance.
As soon as the idpbuilder works correctly on bare metal, the next step is to apply it to an OSC instance.
Append this lines to /etc/hosts
127.0.0.1 gitea.cnoe.localtest.me
127.0.0.1 cnoe.localtest.me
Install nginx by executing:
sudo apt install nginx
Replace /etc/nginx/sites-enabled/default with the following content:
server {
listen 8443 ssl default_server;
listen [::]:8443 ssl default_server;
include snippets/snakeoil.conf;
location / {
proxy_pass http://10.5.0.20:80;
proxy_http_version 1.1;
proxy_cache_bypass $http_upgrade;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Start nginx by executing:
sudo systemctl enable nginx
sudo systemctl restart nginx
For building idpbuilder the source code needs to be downloaded and compiled:
git clone https://github.com/cnoe-io/idpbuilder.git
cd idpbuilder
go build
The idpbuilder binary will be created in the current directory.
Open the idpbuilder folder in VS Code:
code .
Create a new launch setting. Add the "args" parameter to the launch setting:
{
"version": "0.2.0",
"configurations": [
{
"name": "Launch Package",
"type": "go",
"request": "launch",
"mode": "auto",
"program": "${fileDirname}",
"args": ["create", "--use-path-routing", "--package", "https://github.com/cnoe-io/stacks//ref-implementation"]
}
]
}
Talos by default will create docker containers, similar to KIND. Create the cluster by executing:
talosctl cluster create
mkdir -p localpathprovisioning
cd localpathprovisioning
cat > localpathprovisioning.yaml <<EOF
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- github.com/rancher/local-path-provisioner/deploy?ref=v0.0.26
patches:
- patch: |-
kind: ConfigMap
apiVersion: v1
metadata:
name: local-path-config
namespace: local-path-storage
data:
config.json: |-
{
"nodePathMap":[
{
"node":"DEFAULT_PATH_FOR_NON_LISTED_NODES",
"paths":["/var/local-path-provisioner"]
}
]
}
- patch: |-
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-path
annotations:
storageclass.kubernetes.io/is-default-class: "true"
- patch: |-
apiVersion: v1
kind: Namespace
metadata:
name: local-path-storage
labels:
pod-security.kubernetes.io/enforce: privileged
EOF
kustomize build | kubectl apply -f -
rm localpathprovisioning.yaml kustomization.yaml
cd ..
rmdir localpathprovisioning
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.14.8/config/manifests/metallb-native.yaml
sleep 50
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 10.5.0.20-10.5.0.130
EOF
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: homelab-l2
namespace: metallb-system
spec:
ipAddressPools:
- first-pool
EOF
helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespace
sleep 30
Edit the function Run in pkg/build/build.go and comment out the creation of the KIND cluster:
/*setupLog.Info("Creating kind cluster")
if err := b.ReconcileKindCluster(ctx, recreateCluster); err != nil {
return err
}*/
Compile the idpbuilder
go build
Then, in VS Code, switch to main.go in the root directory of the idpbuilder and start debugging.
At the end of the idpbuilder execution a link of the installed ArgoCD is shown. The credentianls for access can be obtained by executing:
./idpbuilder get secrets
A Kubernetes config is created in the default location $HOME/.kube/config. A management of the Kubernetes config is recommended to not unintentionally delete acces to other clusters like the OSC.
To show all running Talos nodes execute:
kubectl get nodes -o wide
To see all running pods:
kubectl get pods -o wide
The cluster can be deleted by executing:
talosctl cluster destroy
Required:
Add *.cnoe.localtest.me to the Talos cluster DNS, pointing to the host device IP address, which runs nginx.
Create a SSL certificate with cnoe.localtest.me as common name. Edit the nginx config to load this certificate. Configure idpbuilder to distribute this certificate instead of the one idpbuilder distributes by idefault.
Optimizations:
Implement an idpbuilder uninstall. This is specially important when working on the OSC instance.
Remove or configure gitea.cnoe.localtest.me, it seems not to work even in the idpbuilder local installation with KIND.
Improvements to the idpbuilder to support Kubernetes instances other then KIND. This can either be done by parametrization or by utilizing Terraform / OpenTOFU or Crossplane.
The idpbuilder supports creating platforms using either path based or subdomain based routing:
idpbuilder create --log-level debug --package https://github.com/cnoe-io/stacks//ref-implementation
idpbuilder create --use-path-routing --log-level debug --package https://github.com/cnoe-io/stacks//ref-implementation
However, even though argo does report all deployments as green eventually, not the entire demo is actually functional (verification?). This is due to hardcoded values that for example point to the path-routed location of gitea to access git repos. Thus, backstage might not be able to access them.
Within the demo / ref-implementation, a simple search & replace is suggested to change urls to fit the given environment. But proper scripting/templating could take care of that as the hostnames and necessary properties should be available. This is, however, a tedious and repetitive task one has to keep in mind throughout the entire system, which might lead to an explosion of config options in the future. Code that addresses correct routing is located in both the stack templates and the idpbuilder code.
For the most part, components communicate with either the cluster API using the default DNS or with each other via http(s) using the public DNS/hostname (+ path-routing scheme). The latter is necessary due to configs that are visible and modifiable by users. This includes for example argocd config for components that has to sync to a gitea git repo. Using the same URL for internal and external resolution is imperative.
The idpbuilder achieves transparent internal DNS resolution by overriding the public DNS name in the cluster’s internal DNS server (coreDNS). Subsequently, within the cluster requests to the public hostnames resolve to the IP of the internal ingress controller service. Thus, internal and external requests take a similar path and run through proper routing (rewrites, ssl/tls, etc).
One has to keep in mind that some specific app features might not work properly or without haxx when using path based routing (e.g. docker registry in gitea). Futhermore, supporting multiple setup strategies will become cumbersome as the platforms grows. We should probably only support one type of setup to keep the system as simple as possible, but allow modification if necessary.
DNS solutions like nip.io or the already used localtest.me mitigate the
need for path based routing
HTTP is a cornerstone of the internet due to its high flexibility. Starting
from HTTP/1.1 each request in the protocol contains among others a path and a
Hostname in its header. While an HTTP request is sent to a single IP address
/ server, these two pieces of data allow (distributed) systems to handle
requests in various ways.
$ curl -v http://google.com/something > /dev/null
* Connected to google.com (2a00:1450:4001:82f::200e) port 80
* using HTTP/1.x
> GET /something HTTP/1.1
> Host: google.com
> User-Agent: curl/8.10.1
> Accept: */*
...
Imagine requesting http://myhost.foo/some/file.html, in a simple setup, the
web server myhost.foo resolves to would serve static files from some
directory, /<some_dir>/some/file.html.
In more complex systems, one might have multiple services that fulfill various roles, for example a service that generates HTML sites of articles from a CMS and a service that can convert images into various formats. Using path-routing both services are available on the same host from a user’s POV.
An article served from http://myhost.foo/articles/news1.html would be
generated from the article service and points to an image
http://myhost.foo/images/pic.jpg which in turn is generated by the image
converter service. When a user sends an HTTP request to myhost.foo, they hit
a reverse proxy which forwards the request based on the requested path to some
other system, waits for a response, and subsequently returns that response to
the user.

Such a setup hides the complexity from the user and allows the creation of large distributed, scalable systems acting as a unified entity from the outside. Since everything is served on the same host, the browser is inclined to trust all downstream services. This allows for easier ‘communication’ between services through the browser. For example, cookies could be valid for the entire host and thus authentication data could be forwarded to requested downstream services without the user having to explicitly re-authenticate.
Furthermore, services ‘know’ their user-facing location by knowing their path
and the paths to other services as paths are usually set as a convention and /
or hard-coded. In practice, this makes configuration of the entire system
somewhat easier, especially if you have various environments for testing,
development, and production. The hostname of the system does not matter as one
can use hostname-relative URLs, e.g. /some/service.
Load balancing is also easily achievable by multiplying the number of service instances. Most reverse proxy systems are able to apply various load balancing strategies to forward traffic to downstream systems.
Problems might arise if downstream systems are not built with path-routing in mind. Some systems require to be served from the root of a domain, see for example the container registry spec.
Each downstream service in a distributed system is served from a different
host, typically a subdomain, e.g. serviceA.myhost.foo and
serviceB.myhost.foo. This gives services full control over their respective
host, and even allows them to do path-routing within each system. Moreover,
hostname-routing allows the entire system to create more flexible and powerful
routing schemes in terms of scalability. Intra-system communication becomes
somewhat harder as the browser treats each subdomain as a separate host,
shielding cookies for example form one another.
Each host that serves some services requires a DNS entry that has to be published to the clients (from some DNS server). Depending on the environment this can become quite tedious as DNS resolution on the internet and intranets might have to deviate. This applies to intra-cluster communication as well, as seen with the idpbuilder’s platform. In this case, external DNS resolution has to be replicated within the cluster to be able to use the same URLs to address for example gitea.
The following example depicts DNS-only routing. By defining separate DNS entries for each service / subdomain requests are resolved to the respective servers. In theory, no additional infrastructure is necessary to route user traffic to each service. However, as services are completely separated other infrastructure like authentication possibly has to be duplicated.

When using hostname based routing, one does not have to set different IPs for
each hostname. Instead, having multiple DNS entries pointing to the same set of
IPs allows re-using existing infrastructure. As shown below, a reverse proxy is
able to forward requests to downstream services based on the Host request
parameter. This way specific hostname can be forwarded to a defined service.

At the same time, one could imagine a multi-tenant system that differentiates
customer systems by name, e.g. tenant-1.cool.system and
tenant-2.cool.system. Configured as a wildcard-sytle domain, *.cool.system
could point to a reverse proxy that forwards requests to a tenants instance of
a system, allowing re-use of central infrastructure while still hosting
separate systems per tenant.
The implicit dependency on DNS resolution generally makes this kind of routing
more complex and error-prone as changes to DNS server entries are not always
possible or modifiable by everyone. Also, local changes to your /etc/hosts
file are a constant pain and should be seen as a dirty hack. As mentioned
above, dynamic DNS solutions like nip.io are often helpful in this case.
Path and hostname based routing are the two most common methods of HTTP traffic
routing. They can be used separately but more often they are used in
conjunction. Due to HTTP’s versatility other forms of HTTP routing, for example
based on the Content-Type Header are also very common.
ArgoCD is a Continuous Delivery tool for kubernetes based on GitOps principles.
ELI5: ArgoCD is an application running in kubernetes which monitors Git repositories containing some sort of kubernetes manifests and automatically deploys them to some configured kubernetes clusters.
From ArgoCD’s perspective, applications are defined as custom resource definitions within the kubernetes clusters that ArgoCD monitors. Such a definition describes a source git repository that contains kubernetes manifests, in the form of a helm chart, kustomize, jsonnet definitions or plain yaml files, as well as a target kubernetes cluster and namespace the manifests should be applied to. Thus, ArgoCD is capable of deploying applications to various (remote) clusters and namespaces.
ArgoCD monitors both the source and the destination. It applies changes from
the git repository that acts as the source of truth for the destination as soon
as they occur, i.e. if a change was pushed to the git repository, the change is
applied to the kubernetes destination by ArgoCD. Subsequently, it checks
whether the desired state was established. For example, it verifies that all
resources were created, enough replicas started, and that all pods are in the
running state and healthy.
An ArgoCD deployment mainly consists of 3 main components:
The application controller is a kubernetes operator that synchronizes the live state within a kubernetes cluster with the desired state derived from the git sources. It monitors the live state, can detect derivations, and perform corrective actions. Additionally, it can execute hooks on life cycle stages such as pre- and post-sync.
The repository server interacts with git repositories and caches their state, to reduce the amount of polling necessary. Furthermore, it is responsible for generating the kubernetes manifests from the resources within the git repositories, i.e. executing helm or jsonnet templates.
The API Server is a REST/gRPC Service that allows the Web UI and CLI, as well as other API clients, to interact with the system. It also acts as the callback for webhooks particularly from Git repository platforms such as GitHub or Gitlab to reduce repository polling.
The system primarily stores its configuration as kubernetes resources. Thus, other external storage is not vital.


ArgoCD is one of the core components besides gitea/forgejo that is being bootstrapped by the idpbuilder. Future project creation, e.g. through backstage, relies on the availability of ArgoCD.
After the initial bootstrapping phase, effectively all components in the stack that are deployed in kubernetes are managed by ArgoCD. This includes the bootstrapped components of gitea and ArgoCD which are onboarded afterward. Thus, the idpbuilder is only necessary in the bootstrapping phase of the platform and the technical coordination of all components shifts to ArgoCD eventually.
In general, the creation of new projects and applications should take place in backstop. It is a catalog of software components and best practices that allows developers to grasp and to manage their software portfolio. Underneath, however, the deployment of applications and platform components is managed by ArgoCD. Among others, backstage creates Application CRDs to instruct ArgoCD to manage deployments and subsequently report on their current state.
Initially shamelessly copied from the docs
The CNOE docs do somewhat interchange validation and verification but for the most part they adhere to the general definition:
Validation is used when you check your approach before actually executing an action.
Examples:
Verification describes testing if your ’thing’ complies with your spec
Examples:
It seems that both validation and verification within the CNOE framework are not actually handled by some explicit component but should be addressed throughout the system and workflows.
As stated in the docs, validation takes place in all parts of the stack by enforcing strict API usage and policies (signing, mitigations, security scans etc, see usage of kyverno for example), and using code generation (proven code), linting, formatting, LSP. Consequently, validation of source code, templates, etc is more a best practice rather than a hard fact or feature and it is up to the user to incorporate them into their workflows and pipelines. This is probably due to the complexity of the entire stack and the individual properties of each component and applications.
Verification of artifacts and deployments actually exists in a somewhat similar state. The current CNOE reference-implementation does not provide sufficient verification tooling.
However, as stated in the docs
within the framework cnoe-cli is capable of extremely limited verification of
artifacts within kubernetes. The same verification is also available as a step
within a backstage
plugin. This is pretty
much just a wrapper of the cli tool. The tool consumes CRD-like structures
defining the state of pods and CRDs and checks for their existence within a
live cluster (example).
Depending on the aspiration of ‘verification’ this check is rather superficial and might only suffice as an initial smoke test. Furthermore, it seems like the feature is not actually used within the CNOE stacks repo.
For a live product more in depth verification tools and schemes are necessary to verify the correct configuration and authenticity of workloads, which is, in the context of traditional cloud systems, only achievable to a limited degree.
Existing tools within the stack, e.g. Argo, provide some verification capabilities. But further investigation into the general topic is necessary.
To support local development and usage of crossplane compositions, a crossplane provider is needed. Every big hyperscaler already has support in crossplane (e.g. provider-gcp and provider-aws).
Each provider has two main parts, the provider config and implementations of the cloud resources.
The provider config takes the credentials to log into the cloud provider and provides a token (e.g. a kube config or even a service account) that the implementations can use to provision cloud resources.
The implementations of the cloud resources reflect each type of cloud resource, typical resources are:
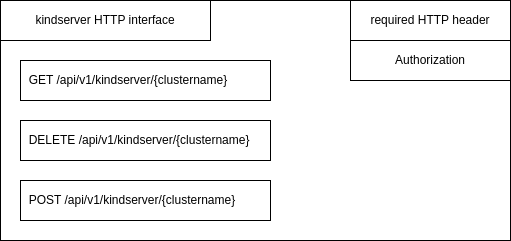
To have the crossplane concepts applied, the provider-kind consists of two components: kindserver and provider-kind.
The kindserver is used to manage local kind clusters. It provides an HTTP REST interface to create, delete and get informations of a running cluster, using an Authorization HTTP header field used as a password:
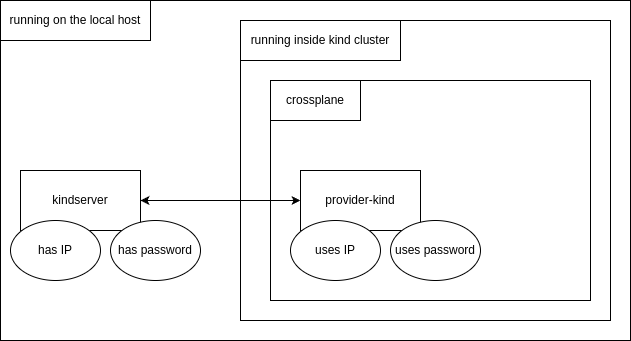
The two properties to connect the provider-kind to kindserver are the IP address and password of kindserver. The IP address is required because the kindserver needs to be executed outside the kind cluster, directly on the local machine, as it need to control kind itself:
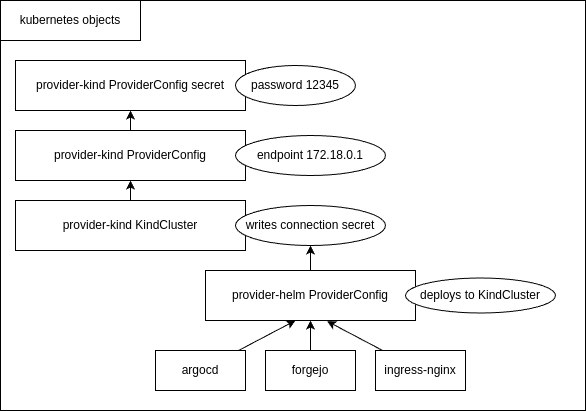
The provider-kind provides two crossplane elements, the ProviderConfig and KindCluster as the (only) cloud resource. The
ProviderConfig is configured with the IP address and password of the running kindserver. The KindCluster type is configured
to use the provided ProviderConfig. Kind clusters can be managed by adding and removing kubernetes manifests of type
KindCluster. The crossplane reconcilation loop makes use of the kindserver HTTP GET method to see if a new cluster needs to be
created by HTTP POST or being removed by HTTP DELETE.
The password used by ProviderConfig is configured as an kubernetes secret, while the kindserver IP address is configured
inside the ProviderConfig as the field endpoint.
When provider-kind created a new cluster by processing a KindCluster manifest, the two providers which are used to deploy applications, provider-helm and provider-kubernetes, can be configured to use the KindCluster.
A Crossplane composition can be created by concaternating different providers and their objects. A composition is managed as a custom resource definition and defined in a single file.
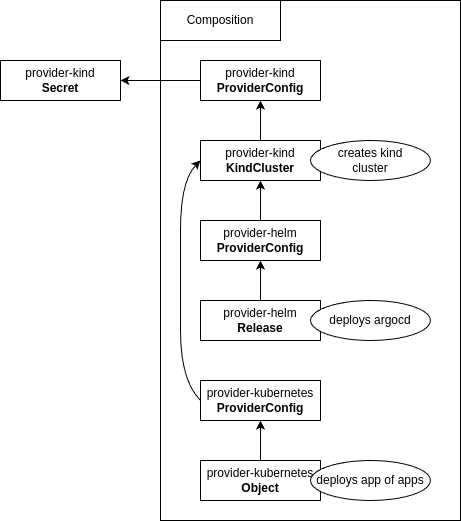
Two kubernetes manifests are defines by provider-kind: ProviderConfig and KindCluster. The third needed kubernetes
object is a secret.
The need for the following inputs arise when developing a provider-kind:
ProviderConfigKindClusterThe following outputs arise:
KindClusterKindClusterKindClusterKindClusterThe kindserver password needs to be defined first. It is realized as a kubernetes secret and contains the password which the kindserver has been configured with:
apiVersion: v1
data:
credentials: MTIzNDU=
kind: Secret
metadata:
name: kind-provider-secret
namespace: crossplane-system
type: Opaque
The IP address of the kindserver endpoint is configured in the provider-kind ProviderConfig. This config also references the kindserver password (kind-provider-secret):
apiVersion: kind.crossplane.io/v1alpha1
kind: ProviderConfig
metadata:
name: kind-provider-config
spec:
credentials:
source: Secret
secretRef:
namespace: crossplane-system
name: kind-provider-secret
key: credentials
endpoint:
url: https://172.18.0.1:7443/api/v1/kindserver
It is suggested that the kindserver runs on the IP of the docker host, so that all kind clusters can access it without extra routing.
The kind config is provided as the field kindConfig in each KindCluster manifest. The manifest also references the provider-kind ProviderConfig (kind-provider-config in the providerConfigRef field):
apiVersion: container.kind.crossplane.io/v1alpha1
kind: KindCluster
metadata:
name: example-kind-cluster
spec:
forProvider:
kindConfig: |
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "ingress-ready=true"
extraPortMappings:
- containerPort: 80
hostPort: 80
protocol: TCP
- containerPort: 443
hostPort: 443
protocol: TCP
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."gitea.cnoe.localtest.me:443"]
endpoint = ["https://gitea.cnoe.localtest.me"]
[plugins."io.containerd.grpc.v1.cri".registry.configs."gitea.cnoe.localtest.me".tls]
insecure_skip_verify = true
providerConfigRef:
name: kind-provider-config
writeConnectionSecretToRef:
namespace: default
name: kind-connection-secret
After the kind cluster has been created, it’s kube config is stored in a kubernetes secret kind-connection-secret which writeConnectionSecretToRef references.
The three outputs can be recieved by getting the KindCluster manifest after the cluster has been created. The KindCluster is
available for reading even before the cluster has been created, but the three outputfields are empty until then. The ready state
will also switch from false to true after the cluster has finally been created.
This fields can be recieved with a standard kubectl get command:
$ kubectl get kindclusters kindcluster-fw252 -o yaml
...
status:
atProvider:
internalIP: 192.168.199.19
kubernetesVersion: v1.31.0
conditions:
- lastTransitionTime: "2024-11-12T18:22:39Z"
reason: Available
status: "True"
type: Ready
- lastTransitionTime: "2024-11-12T18:21:38Z"
reason: ReconcileSuccess
status: "True"
type: Synced
The kube config is stored in a kubernetes secret (kind-connection-secret) which can be accessed after the cluster has been
created:
$ kubectl get kindclusters kindcluster-fw252 -o yaml
...
writeConnectionSecretToRef:
name: kind-connection-secret
namespace: default
...
$ kubectl get secret kind-connection-secret
NAME TYPE DATA AGE
kind-connection-secret connection.crossplane.io/v1alpha1 2 107m
The API endpoint of the new cluster endpoint and it’s kube config kubeconfig is stored in that secret. This values are set in
the Obbserve function of the kind controller of provider-kind. They are set with the special crossplane function managed
ExternalObservation.
The reconciler loop is the heart of every crossplane provider. As it is coupled async, it’s best to describe it working in words:
Internally, the Connect function get’s triggered in the kindcluster controller internal/controller/kindcluster/kindcluster.go
first, to setup the provider and configure it with the kindserver password and IP address of the kindserver.
After that the provider-kind has been configured with the kindserver secret and it’s ProviderConfig, the provider is ready to
be activated by applying a KindCluster manifest to kubernetes.
When the user applies a new KindCluster manifest, a observe loop is started. The provider regulary triggers the Observe
function of the controller. As there has yet been created nothing yet, the controller will return
managed.ExternalObservation{ResourceExists: false} to signal that the kind cluster resource has not been created yet.
As the is a kindserver SDK available, the controller is using the Get function of the SDK to query the kindserver.
The KindCluster is already applied and can be retrieved with kubectl get kindclusters. As the cluster has not been
created yet, it readiness state is false.
In parallel, the Create function is triggered in the controller. This function has acces to the desired kind config
cr.Spec.ForProvider.KindConfig and the name of the kind cluster cr.ObjectMeta.Name. It can now call the kindserver SDK to
create a new cluster with the given config and name. The create function is supposed not to run too long, therefore
it directly returns in the case of provider-kind. The kindserver already knows the name of the new cluster and even it is
not yet ready, it will respond with a partial success.
The observe loops is triggered regulary in parallel. It will be triggered after the create call but before the kind cluster has been created. Now it will get a step further. It gets the information of kindserver, that the cluster is already knows, but not finished creating yet.
After the cluster has been finished creating, the kindserver has all important informations for the provider-kind. That is The API server endpoint of the new cluster and it’s kube config. After another round of the observer loop, the controller gets now the full set of information of kindcluster (cluster ready, it’s API server endpoint and it’s kube config). When this informations has been recieved by the kindserver SDk in form of a JSON file, it is able to signal successfull creating of the cluster. That is done by returning the following structure from inside the observe function:
return managed.ExternalObservation{
ResourceExists: true,
ResourceUpToDate: true,
ConnectionDetails: managed.ConnectionDetails{
xpv1.ResourceCredentialsSecretEndpointKey: []byte(clusterInfo.Endpoint),
xpv1.ResourceCredentialsSecretKubeconfigKey: []byte(clusterInfo.KubeConfig),
},
}, nil
Note that the managed.ConnectionDetails will automatically write the API server endpoint and it’s kube config to the kubernetes
secret which writeConnectionSecretToRefof KindCluster points to.
It also set the availability flag before returning, that will mark the KindCluster as ready:
cr.Status.SetConditions(xpv1.Available())
Before returning, it will also set the informations which are transfered into fields of kindCluster which can be retrieved by a
kubectl get, the kubernetesVersion and the internalIP fields:
cr.Status.AtProvider.KubernetesVersion = clusterInfo.K8sVersion
cr.Status.AtProvider.InternalIP = clusterInfo.NodeIp
Now the KindCluster is setup completly and when it’s data is retrieved by kubectl get, all data is available and it’s readiness
is set to true.
The observer loops continies to be called to enable drift detection. That detection is currently not implemented, but is
prepared for future implementations. When the observer function would detect that the kind cluster with a given name is set
up with a kind config other then the desired, the controller would call the controller Update function, which would
delete the currently runnign kind cluster and recreates it with the desired kind config.
When the user is deleting the KindCluster manifest at a later stage, the Delete function of the controller is triggered
to call the kindserver SDK to delete the cluster with the given name. The observer loop will acknowledge that the cluster
is deleted successfully by retrieving kind cluster not found when the deletion had been successfull. If not, the controller
will trigger the delete function in a loop as well, until the kind cluster has been deleted.
That assembles the reconciler loop.
Each newly created kind cluster has a practially random kubernetes API server endpoint. As the IP address of a new kind cluster can’t determined before creation, the kindserver manages the API server field of the kind config. It will map all kind server kubernets API endpoints on it’s own IP address, but on different ports. That garantees that alls kind clusters can access the kubernetes API endpoints of all other kind clusters by using the docker host IP of the kindserver itself. This is needed as the kube config hardcodes the kubernets API server endpoint. By using the docker host IP but with different ports, every usage of a kube config from one kind cluster to another is working successfully.
The management of the kind config in the kindserver is implemented in the Post function of the kindserver main.go file.
The official way for creating crossplane providers is to use the provider-template. Process the following steps to create a new provider.
First, clone the provider-template. The commit ID when this howto has been written is 2e0b022c22eb50a8f32de2e09e832f17161d7596. Rename the new folder after cloning.
git clone https://github.com/crossplane/provider-template.git
mv provider-template provider-kind
cd provider-kind/
The informations in the provided README.md are incomplete. Folow this steps to get it running:
Please use bash for the next commands (
${type,,}e.g. is not a mistake)
make submodules
export provider_name=Kind # Camel case, e.g. GitHub
make provider.prepare provider=${provider_name}
export group=container # lower case e.g. core, cache, database, storage, etc.
export type=KindCluster # Camel casee.g. Bucket, Database, CacheCluster, etc.
make provider.addtype provider=${provider_name} group=${group} kind=${type}
sed -i "s/sample/${group}/g" apis/${provider_name,,}.go
sed -i "s/mytype/${type,,}/g" internal/controller/${provider_name,,}.go
Patch the Makefile:
dev: $(KIND) $(KUBECTL)
@$(INFO) Creating kind cluster
+ @$(KIND) delete cluster --name=$(PROJECT_NAME)-dev
@$(KIND) create cluster --name=$(PROJECT_NAME)-dev
@$(KUBECTL) cluster-info --context kind-$(PROJECT_NAME)-dev
- @$(INFO) Installing Crossplane CRDs
- @$(KUBECTL) apply --server-side -k https://github.com/crossplane/crossplane//cluster?ref=master
+ @$(INFO) Installing Crossplane
+ @helm install crossplane --namespace crossplane-system --create-namespace crossplane-stable/crossplane --wait
@$(INFO) Installing Provider Template CRDs
@$(KUBECTL) apply -R -f package/crds
@$(INFO) Starting Provider Template controllers
Generate, build and execute the new provider-kind:
make generate
make build
make dev
Now it’s time to add the required fields (internalIP, endpoint, etc.) to the spec fields in go api sources found in:
The file apis/kind.go may also be modified. The word sample can be replaces with container in our case.
When that’s done, the yaml specifications needs to be modified to also include the required fields (internalIP, endpoint, etc.)
Next, a kindserver SDK can be implemented. That is a helper class which encapsulates the get, create and delete HTTP calls to the kindserver. Connection infos (kindserver IP address and password) will be stored by the constructor.
After that we can add the usage of the kindclient sdk in kindcluster controller internal/controller/kindcluster/kindcluster.go.
Finally we can update the Makefile to better handle the primary kind cluster creation and adding of a cluster role binding
so that crossplane can access the KindCluster objects. Examples and updating the README.md will finish the development.
All this steps are documented in: https://forgejo.edf-bootstrap.cx.fg1.ffm.osc.live/DevFW/provider-kind/pulls/1
Every provider-kind release needs to be tagged first in the git repository:
git tag v0.1.0
git push origin v0.1.0
Next, make sure you have docker logged in into the target registry:
docker login forgejo.edf-bootstrap.cx.fg1.ffm.osc.live
Now it’s time to specify the target registry, build the provider-kind for ARM64 and AMD64 CPU architectures and publish it to the target registry:
XPKG_REG_ORGS_NO_PROMOTE="" XPKG_REG_ORGS="forgejo.edf-bootstrap.cx.fg1.ffm.osc.live/richardrobertreitz" make build.all publish BRANCH_NAME=main
The parameter BRANCH_NAME=main is needed when the tagging and publishing happens from another branch. The version of the provider-kind that of the tag name. The output of the make call ends then like this:
$ XPKG_REG_ORGS_NO_PROMOTE="" XPKG_REG_ORGS="forgejo.edf-bootstrap.cx.fg1.ffm.osc.live/richardrobertreitz" make build.all publish BRANCH_NAME=main
...
14:09:19 [ .. ] Skipping image publish for docker.io/provider-kind:v0.1.0
Publish is deferred to xpkg machinery
14:09:19 [ OK ] Image publish skipped for docker.io/provider-kind:v0.1.0
14:09:19 [ .. ] Pushing package forgejo.edf-bootstrap.cx.fg1.ffm.osc.live/richardrobertreitz/provider-kind:v0.1.0
xpkg pushed to forgejo.edf-bootstrap.cx.fg1.ffm.osc.live/richardrobertreitz/provider-kind:v0.1.0
14:10:19 [ OK ] Pushed package forgejo.edf-bootstrap.cx.fg1.ffm.osc.live/richardrobertreitz/provider-kind:v0.1.0
After publishing, the provider-kind can be installed in-cluster similar to other providers like provider-helm and provider-kubernetes. To install it apply the following manifest:
apiVersion: pkg.crossplane.io/v1
kind: Provider
metadata:
name: provider-kind
spec:
package: forgejo.edf-bootstrap.cx.fg1.ffm.osc.live/richardrobertreitz/provider-kind:v0.1.0
The output of kubectl get providers:
$ kubectl get providers
NAME INSTALLED HEALTHY PACKAGE AGE
provider-helm True True xpkg.upbound.io/crossplane-contrib/provider-helm:v0.19.0 38m
provider-kind True True forgejo.edf-bootstrap.cx.fg1.ffm.osc.live/richardrobertreitz/provider-kind:v0.1.0 39m
provider-kubernetes True True xpkg.upbound.io/crossplane-contrib/provider-kubernetes:v0.15.0 38m
The provider-kind can now be used.
edfbuilderTogether with the implemented provider-kind and it’s config to create a composition which can create kind clusters and the ability to deploy helm and kubernetes objects in the newly created cluster.
A composition is realized as a custom resource definition (CRD) considting of three parts:
The definition of the CRD will most probably contain one additional fiel, the ArgoCD repository URL to easily select the stacks which should be deployed:
apiVersion: apiextensions.crossplane.io/v1
kind: CompositeResourceDefinition
metadata:
name: edfbuilders.edfbuilder.crossplane.io
spec:
connectionSecretKeys:
- kubeconfig
group: edfbuilder.crossplane.io
names:
kind: EDFBuilder
listKind: EDFBuilderList
plural: edfbuilders
singular: edfbuilders
versions:
- name: v1alpha1
served: true
referenceable: true
schema:
openAPIV3Schema:
description: A EDFBuilder is a composite resource that represents a K8S Cluster with edfbuilder Installed
type: object
properties:
spec:
type: object
properties:
repoURL:
type: string
description: URL to ArgoCD stack of stacks repo
required:
- repoURL
This is a shortened version of the file examples/composition_deprecated/composition.yaml. It combines a KindCluster with
deployments of of provider-helm and provider-kubernetes. Note that the ProviderConfig and the kindserver secret has already been
applied to kubernetes (by the Makefile) before applying this composition.
apiVersion: apiextensions.crossplane.io/v1
kind: Composition
metadata:
name: edfbuilders.edfbuilder.crossplane.io
spec:
writeConnectionSecretsToNamespace: crossplane-system
compositeTypeRef:
apiVersion: edfbuilder.crossplane.io/v1alpha1
kind: EDFBuilder
resources:
### kindcluster
- base:
apiVersion: container.kind.crossplane.io/v1alpha1
kind: KindCluster
metadata:
name: example
spec:
forProvider:
kindConfig: |
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "ingress-ready=true"
extraPortMappings:
- containerPort: 80
hostPort: 80
protocol: TCP
- containerPort: 443
hostPort: 443
protocol: TCP
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."gitea.cnoe.localtest.me:443"]
endpoint = ["https://gitea.cnoe.localtest.me"]
[plugins."io.containerd.grpc.v1.cri".registry.configs."gitea.cnoe.localtest.me".tls]
insecure_skip_verify = true
providerConfigRef:
name: example-provider-config
writeConnectionSecretToRef:
namespace: default
name: my-connection-secret
### helm provider config
- base:
apiVersion: helm.crossplane.io/v1beta1
kind: ProviderConfig
spec:
credentials:
source: Secret
secretRef:
namespace: default
name: my-connection-secret
key: kubeconfig
patches:
- fromFieldPath: metadata.name
toFieldPath: metadata.name
readinessChecks:
- type: None
### ingress-nginx
- base:
apiVersion: helm.crossplane.io/v1beta1
kind: Release
metadata:
annotations:
crossplane.io/external-name: ingress-nginx
spec:
rollbackLimit: 99999
forProvider:
chart:
name: ingress-nginx
repository: https://kubernetes.github.io/ingress-nginx
version: 4.11.3
namespace: ingress-nginx
values:
controller:
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
hostPort:
enabled: true
terminationGracePeriodSeconds: 0
service:
type: NodePort
watchIngressWithoutClass: true
nodeSelector:
ingress-ready: "true"
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Equal"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/control-plane"
operator: "Equal"
effect: "NoSchedule"
publishService:
enabled: false
extraArgs:
publish-status-address: localhost
# added for idpbuilder
enable-ssl-passthrough: ""
# added for idpbuilder
allowSnippetAnnotations: true
# added for idpbuilder
config:
proxy-buffer-size: 32k
use-forwarded-headers: "true"
patches:
- fromFieldPath: metadata.name
toFieldPath: spec.providerConfigRef.name
### kubernetes provider config
- base:
apiVersion: kubernetes.crossplane.io/v1alpha1
kind: ProviderConfig
spec:
credentials:
source: Secret
secretRef:
namespace: default
name: my-connection-secret
key: kubeconfig
patches:
- fromFieldPath: metadata.name
toFieldPath: metadata.name
readinessChecks:
- type: None
### kubernetes argocd stack of stacks application
- base:
apiVersion: kubernetes.crossplane.io/v1alpha2
kind: Object
spec:
forProvider:
manifest:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: edfbuilder
namespace: argocd
labels:
env: dev
spec:
destination:
name: in-cluster
namespace: argocd
source:
path: registry
repoURL: 'https://gitea.cnoe.localtest.me/giteaAdmin/edfbuilder-shoot'
targetRevision: HEAD
project: default
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=true
patches:
- fromFieldPath: metadata.name
toFieldPath: spec.providerConfigRef.name
Set this values to allow many kind clusters running in parallel, if needed:
sudo sysctl fs.inotify.max_user_watches=524288
sudo sysctl fs.inotify.max_user_instances=512
To make the changes persistent, edit the file /etc/sysctl.conf and add these lines:
fs.inotify.max_user_watches = 524288
fs.inotify.max_user_instances = 512
Start provider-kind:
make build
kind delete clusters $(kind get clusters)
kind create cluster --name=provider-kind-dev
DOCKER_HOST_IP="$(docker inspect $(docker ps | grep kindest | awk '{ print $1 }' | head -n1) | jq -r .[0].NetworkSettings.Networks.kind.Gateway)" make dev
Wait until debug output of the provider-kind is shown:
...
namespace/crossplane-system configured
secret/example-provider-secret created
providerconfig.kind.crossplane.io/example-provider-config created
14:49:50 [ .. ] Starting Provider Kind controllers
2024-11-12T14:49:54+01:00 INFO controller-runtime.metrics Starting metrics server
2024-11-12T14:49:54+01:00 INFO Starting EventSource {"controller": "providerconfig/providerconfig.kind.crossplane.io", "controllerGroup": "kind.crossplane.io", "controllerKind": "ProviderConfig", "source": "kind source: *v1alpha1.ProviderConfig"}
2024-11-12T14:49:54+01:00 INFO Starting EventSource {"controller": "providerconfig/providerconfig.kind.crossplane.io", "controllerGroup": "kind.crossplane.io", "controllerKind": "ProviderConfig", "source": "kind source: *v1alpha1.ProviderConfigUsage"}
2024-11-12T14:49:54+01:00 INFO Starting Controller {"controller": "providerconfig/providerconfig.kind.crossplane.io", "controllerGroup": "kind.crossplane.io", "controllerKind": "ProviderConfig"}
2024-11-12T14:49:54+01:00 INFO Starting EventSource {"controller": "managed/kindcluster.container.kind.crossplane.io", "controllerGroup": "container.kind.crossplane.io", "controllerKind": "KindCluster", "source": "kind source: *v1alpha1.KindCluster"}
2024-11-12T14:49:54+01:00 INFO Starting Controller {"controller": "managed/kindcluster.container.kind.crossplane.io", "controllerGroup": "container.kind.crossplane.io", "controllerKind": "KindCluster"}
2024-11-12T14:49:54+01:00 INFO controller-runtime.metrics Serving metrics server {"bindAddress": ":8080", "secure": false}
2024-11-12T14:49:54+01:00 INFO Starting workers {"controller": "providerconfig/providerconfig.kind.crossplane.io", "controllerGroup": "kind.crossplane.io", "controllerKind": "ProviderConfig", "worker count": 10}
2024-11-12T14:49:54+01:00 DEBUG provider-kind Reconciling {"controller": "providerconfig/providerconfig.kind.crossplane.io", "request": {"name":"example-provider-config"}}
2024-11-12T14:49:54+01:00 INFO Starting workers {"controller": "managed/kindcluster.container.kind.crossplane.io", "controllerGroup": "container.kind.crossplane.io", "controllerKind": "KindCluster", "worker count": 10}
2024-11-12T14:49:54+01:00 INFO KubeAPIWarningLogger metadata.finalizers: "in-use.crossplane.io": prefer a domain-qualified finalizer name to avoid accidental conflicts with other finalizer writers
2024-11-12T14:49:54+01:00 DEBUG provider-kind Reconciling {"controller": "providerconfig/providerconfig.kind.crossplane.io", "request": {"name":"example-provider-config"}}
Start kindserver:
see kindserver/README.md
When kindserver is started:
cd examples/composition_deprecated
kubectl apply -f definition.yaml
kubectl apply -f composition.yaml
kubectl apply -f cluster.yaml
List the created elements, wait until the new cluster is created, then switch back to the primary cluster:
kubectl config use-context kind-provider-kind-dev
Show edfbuilder compositions:
kubectl get edfbuilders
NAME SYNCED READY COMPOSITION AGE
kindcluster True True edfbuilders.edfbuilder.crossplane.io 4m45s
Show kind clusters:
kubectl get kindclusters
NAME READY SYNCED EXTERNAL-NAME INTERNALIP VERSION AGE
kindcluster-wlxrt True True kindcluster-wlxrt 192.168.199.19 v1.31.0 5m12s
Show helm deployments:
kubectl get releases
NAME CHART VERSION SYNCED READY STATE REVISION DESCRIPTION AGE
kindcluster-29dgf ingress-nginx 4.11.3 True True deployed 1 Install complete 5m32s
kindcluster-w2dxl forgejo 10.0.2 True True deployed 1 Install complete 5m32s
kindcluster-x8x9k argo-cd 7.6.12 True True deployed 1 Install complete 5m32s
Show kubernetes objects:
kubectl get objects
NAME KIND PROVIDERCONFIG SYNCED READY AGE
kindcluster-8tbv8 ConfigMap kindcluster True True 5m50s
kindcluster-9lwc9 ConfigMap kindcluster True True 5m50s
kindcluster-9sgmd Deployment kindcluster True True 5m50s
kindcluster-ct2h7 Application kindcluster True True 5m50s
kindcluster-s5knq ConfigMap kindcluster True True 5m50s
Open the composition in VS Code: examples/composition_deprecated/composition.yaml
Currently missing is the third and final part, the imperative steps which need to be processed:
Connecting the definition field (ArgoCD repo URL) and composition interconnects (function-patch-and-transform) are also missing.
Grafana is an open-source monitoring solution that enables viusalization of metrics and logs. Prometheus is an open-source monitoring and alerting system which collects metrics from services and allows the metrics to be shown in Grafana.
The application ist started in edfbuilder/kind/stacks/core/kube-prometheus.yaml. The application has the sync option spec.syncPolicy.syncOptions ServerSideApply=true. This is necessary, since kube-prometheus-stack exceeds the size limit for secrets and without this option a sync attempt will fail and throw an exception. The Helm values file edfbuilder/kind/stacks/core/kube-prometheus/values.yaml contains configuration values: grafana.additionalDataSources contains Loki as a Grafana Data Source. grafana.ingress contains the Grafana ingress configuratione, like the host url (cnoe.localtest.me). grafana.sidecar.dashboards contains necessary configurations so additional user defined dashboards are loaded when Grafana is started. grafana.grafana.ini.server contains configuration details that are necessary, so the ingress points to the correct url.
Once Grafana is running it is accessible under https://cnoe.localtest.me/grafana. Many preconfigured dashboards can be used by klicking the menu option Dashboards.
The application edfbuilder/kind/stacks/core/kube-prometheus.yaml is used to import new Loki dashboards. Examples for imported dashboards can be found in the folder edfbuilder/kind/stacks/core/kube-prometheus/dashboards.
It is possible to add your own dashboards: Dashboards must be in JSON format. To add your own dashboard create a new ConfigMap in YAML format using onw of the examples as a blueprint. The new dashboard in JSON format has to be added as the value for data.k8s-dashboard-[…].json like in the examples. (It is important to use a unique name for data.k8s-dashboard-[…].json for each dashboard.)
Currently preconfigured dashboards include several dahboards for Loki and a dashboard to showcase Nginx-Ingress metrics.
Kyverno is a policy engine for Kubernetes designed to enforce, validate, and mutate configurations of Kubernetes resources. It allows administrators to define policies as Kubernetes custom resources (CRDs) without requiring users to learn a new language or system.
Kyverno simplifies governance and compliance in Kubernetes environments by automating policy management and ensuring best practices are followed.
Same as for idpbuilder installation
For building idpbuilder the source code needs to be downloaded and compiled:
git clone https://github.com/cnoe-io/idpbuilder.git
cd idpbuilder
go build
To start the idpbuilder with kyverno integration execute the following command:
idpbuilder create --use-path-routing -p https://github.com/cnoe-io/stacks//ref-implementation -p https://github.com/cnoe-io/stacks//kyverno-integration
After this step, you can see in ArgoCD that kyverno was installed
The application Grafana Loki is started in edfbuilder/kind/stacks/core/loki.yaml. Loki is started in microservices mode and contains the components ingester, distributor, querier, and query-frontend. The Helm values file edfbuilder/kind/stacks/core/loki/values.yaml contains configuration values.
The application Grafana Promtail is started in edfbuilder/kind/stacks/core/promtail.yaml. The Helm values file edfbuilder/kind/stacks/core/promtail/values.yaml contains configuration values.
This onboarding section is for you when are new to IPCEI-CIS subproject ‘Edge Developer Framework (EDF)’ and you want to know about
Please do not think this story and the underlying assumptions are carved in stone!
Pls be aware of the the following domain and task structure of our mission:

The ‘Edge Developer Framework’ is both the project and the product we are working for. Out of the leading ‘Portfolio Document’ we derive requirements which are ought to be fulfilled by Platform Engineering.
This is our claim!
Reference: IPCEI-CIS Project Portfolio Version 5.9, November 17, 2023
e. Development of DTAG/TSI Edge Developer Framework
| capability | major novelties | ||
|---|---|---|---|
| e.1. Edge Developer full service framework (SDK + day1 +day2 support for edge installations) | Adaptive CI/CD pipelines for heterogeneous edge environments | Decentralized and self healing deployment and management | edge-driven monitoring and analytics |
| e.2. Built-in sustainability optimization in Edge developer framework | sustainability optimized edge-aware CI/CD tooling | sustainability-optimized configuration management | sustainability-optimized efficient deployment strategies |
| e.3. Sustainable-edge management-optimized user interface for edge developers | sustainability optimized User Interface | Ai-Enabled intelligent experience | AI/ML-based automated user experience testing and optimization |
DTAG will also focus on developing an easy-to-use Edge Developer framework for software developers to manage the whole lifecycle of edge applications, i.e. for day-0-, day-1- and up to day-2- operations. With this DTAG will strongly enable the ecosystem building for the entire IPCEI-CIS edge to cloud continuum and ensure openness and accessibility for anyone or any company to make use and further build on the edge to cloud continuum. Providing the use of the tool framework via an open-source approach will further reduce entry barriers and enhance the openness and accessibility for anyone or any organization (see innovations e.).
e.1 Edge developer full-service framework
This tool set and related best practices and guidelines will adapt, enhance and further innovate DevOps principles and their related, necessary supporting technologies according to the specific requirements and constraints associated with edge or edge cloud development, in order to keep the healthy and balanced innovation path on both sides, the (software) development side and the operations side in the field of DevOps.
Next we’ll see how these requirements seem to be fulfilled by platforms!
Since 2010 we have DevOps. This brings increasing delivery speed and efficiency at scale. But next we got high ‘cognitive loads’ for developers and production congestion due to engineering lifecycle complexity. So we need on top of DevOps an instrumentation to ensure and enforce speed, quality, security in modern, cloud native software development. This instrumentation is called ‘golden paths’ in intenal develoepr platforms (IDP).
Let’s start with a look into the history of platform engineering. A good starting point is Humanitec, as they nowadays are one of the biggest players (’the market leader in IDPs.’) in platform engineering.
They create lots of beautiful articles and insights, their own platform products and basic concepts for the platform architecture (we’ll meet this later on!).

In The Evolution of Platform Engineering the interconnection inbetween DevOps, Cloud Native, and the Rise of Platform Engineering is nicely presented and summarizes:
Platform engineering can be broadly defined as the discipline of designing and building toolchains and workflows that enable self-service capabilities for software engineering organizations
When looking at these ‘capabilities’, we have CNCF itself:
There is a CNCF working group which provides the definition of Capabilities of platforms and shows a first idea of the layered architecture of platforms as service layer for developers (“product and application teams”):

Important: As Platform engineer also notice the platform-eng-maturity-model
Or, in another illustration for the platform as a developer service interface, which also defines the ‘Platform Engineering Team’ inbetween:

As we now have evidence about the nescessity of platforms, their capabilities and benefit as self service layer for developers, we want to thin about how to build them.
First of all some important wording to motivate the important term ‘internal developer platfoms’ (we will go into this deeper in the next section with the general architecture), which is clear today, but took years to evolve and is still some amount if effort to jump in:
Build or buy - this is also in pltaform engineering a tweaked discussion, which one of the oldest player answers like this with some oppinioated internal capability structuring:
[internaldeveloperplatform.org[(https://internaldeveloperplatform.org/platform-tooling/)
Next we’ll see how these concepts got structured!
Words are hard, it seems. ‘Platform’ is just about the most ambiguous term we could use for an approach that is super-important for increasing delivery speed and efficiency at scale. Hence the title of this article, here is what I’ve been talking about most recently.
Definitions for software and hardware platforms abound, generally describing an operating environment upon which applications can execute and which provides reusable capabilities such as file systems and security.
Zooming out, at an organisational level a ‘digital platform’ has similar characteristics - an operating environment which teams can build upon to deliver product features to customers more quickly, supported by reusable capabilities.
A digital platform is a foundation of self-service APIs, tools, services, knowledge and support which are arranged as a compelling internal product. Autonomous delivery teams can make use of the platform to deliver product features at a higher pace, with reduced co-ordination.
common-myths-about-platform-engineering
This is about you :-), the platform engineering team:
how-to-build-your-platform-engineering-team
https://www.qovery.com/blog/devops-vs-platform-engineering-is-there-a-difference/
When defining and setting up platforms next two intrinsic problems arise:
Thus the technology of ‘Platform Orchestrating’ emerged recently, in late 2023.
An interesting difference between the CNCF white paper building blocks and them from Internaldeveloperplatforms is the part orchestrators.
This is something extremely new since late 2023 - the rise of the automation of platform engineering!
It was Humanitec creating a definition of platform architecture, as they needed to defien what they are building with their ‘orchestrator’:

Based on the refence architecture you next can build - or let’s say ‘orchestrate’ - different platform implementations, based on declarative definitions of the platform design.
https://humanitec.com/reference-architectures

Hint: There is a slides tool provided by McKinsey to set up your own platform deign based on the reference architecture
Next we’ll see how we are going to do platform orchestration with CNOE!
You remember the capability mappings from the time before orchestration? Here we have a similar setup based on Humanitecs platform engineering status ewhite paper:

In late 2023 platform orchestration raised - the discipline of declarativley dinfing, building, orchestarting and reconciling building blocks of (digital) platforms.
The famost one ist the platform orchestrator from Humanitec. They provide lots of concepts and access, also open sourced tools and schemas. But they do not have open sourced the ocheastartor itself.
Thus we were looking for open source means for platform orchestrating and found CNOE.
When we want to set up a complete platform we expect to have
This is what CNOE delivers:
For seamless transition into a CNOE-compliant delivery pipeline, CNOE will aim at delivering “packaging specifications”, “templating mechanisms”, as well as “deployer technologies”, an example of which is enabled via the idpBuilder tool we have released. The combination of templates, specifications, and deployers allow for bundling and then unpacking of CNOE recommended tools into a user’s DevOps environment. This enables teams to share and deliver components that are deemed to be the best tools for the job.
CNOE architecture looks a bit different than the reference architecture from Humanitec, but this just a matter of details and arrangement:
Hint: This has to be further investigated! This is subject to an Epic.

You have a definition of all the capabilities here:
Hint: This has to be further investigated! This is subject to an Epic.

CNOE calls the schema and templating mechnanism ‘stacks’:
Hint: This has to be further investigated! This is subject to an Epic.
There are already some example stacks:

Next we’ll see how a CNOE stacked Internal Developer Platform is deployed on you local laptop!
CNOE is a ‘Platform Engineering Framework’ (Danger: Our wording!) - it is open source and locally runnable.
It consists of the orchestrator ‘idpbuilder’ and both of some predefined building blocks and also some predefined platform configurations.
The orchestrator in CNOE is called ‘idpbuilder’. It is locally installable binary
A typipcal first setup ist described here: https://cnoe.io/docs/reference-implementation/technology
# this is a local linux shell
# check local installation
type idpbuilder
idpbuilder is /usr/local/bin/idpbuilder
# check version
idpbuilder version
idpbuilder 0.8.0-nightly.20240914 go1.22.7 linux/amd64
# do some completion and aliasing
source <(idpbuilder completion bash)
alias ib=idpbuilder
complete -F __start_idpbuilder ib
# check and remove all existing kind clusters
kind delete clusters --all
kind get clusters
# sth. like 'No kind clusters found.'
# run
$ib create --use-path-routing --log-level debug --package-dir https://github.com/cnoe-io/stacks//ref-implementation
You get output like
stl@ubuntu-vpn:~/git/mms/ipceicis-developerframework$ idpbuilder create
Oct 1 10:09:18 INFO Creating kind cluster logger=setup
Oct 1 10:09:18 INFO Runtime detected logger=setup provider=docker
########################### Our kind config ############################
# Kind kubernetes release images https://github.com/kubernetes-sigs/kind/releases
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
image: "kindest/node:v1.30.0"
labels:
ingress-ready: "true"
extraPortMappings:
- containerPort: 443
hostPort: 8443
protocol: TCP
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."gitea.cnoe.localtest.me:8443"]
endpoint = ["https://gitea.cnoe.localtest.me"]
[plugins."io.containerd.grpc.v1.cri".registry.configs."gitea.cnoe.localtest.me".tls]
insecure_skip_verify = true
######################### config end ############################
Goto https://cnoe.io/docs/reference-implementation/installations/idpbuilder/usage, and follow the flow
You may have seen: when starting idpbuilder without an existing cluster named localdev it first creates this cluster by calling kindwith an internally defined config.
It’s an important feature of idpbuilder that it will set up on an existing cluster localdev when called several times in a row e.g. to append new packages to the cluster.
That’s why we here first create the kind cluster localdevitself:
cat << EOF | kind create cluster --name localdev --config=-
# Kind kubernetes release images https://github.com/kubernetes-sigs/kind/releases
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
image: "kindest/node:v1.30.0"
labels:
ingress-ready: "true"
extraPortMappings:
- containerPort: 443
hostPort: 8443
protocol: TCP
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."gitea.cnoe.localtest.me:8443"]
endpoint = ["https://gitea.cnoe.localtest.me"]
[plugins."io.containerd.grpc.v1.cri".registry.configs."gitea.cnoe.localtest.me".tls]
insecure_skip_verify = true
# alternatively, if you have the kind config as file:
kind create cluster --name localdev --config kind-config.yaml
A typical raw kind setup kubernetes cluster would look like this with respect to running pods:
be sure all pods are in status ‘running’
stl@ubuntu-vpn:~/git/mms/idpbuilder$ k get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-76f75df574-lb7jz 1/1 Running 0 15s
kube-system coredns-76f75df574-zm2wp 1/1 Running 0 15s
kube-system etcd-localdev-control-plane 1/1 Running 0 27s
kube-system kindnet-8qhd5 1/1 Running 0 13s
kube-system kindnet-r4d6n 1/1 Running 0 15s
kube-system kube-apiserver-localdev-control-plane 1/1 Running 0 27s
kube-system kube-controller-manager-localdev-control-plane 1/1 Running 0 27s
kube-system kube-proxy-vrh64 1/1 Running 0 15s
kube-system kube-proxy-w8ks9 1/1 Running 0 13s
kube-system kube-scheduler-localdev-control-plane 1/1 Running 0 27s
local-path-storage local-path-provisioner-6f8956fb48-6fvt2 1/1 Running 0 15s
Now we run idpbuilder the first time:
# now idpbuilder reuses the already existing cluster
# pls apply '--use-path-routing' otherwise as we discovered currently the service resolving inside the cluster won't work
ib create --use-path-routing
stl@ubuntu-vpn:~/git/mms/idpbuilder$ ib create --use-path-routing
Oct 1 10:32:50 INFO Creating kind cluster logger=setup
Oct 1 10:32:50 INFO Runtime detected logger=setup provider=docker
Oct 1 10:32:50 INFO Cluster already exists logger=setup cluster=localdev
Oct 1 10:32:50 INFO Adding CRDs to the cluster logger=setup
Oct 1 10:32:51 INFO Setting up CoreDNS logger=setup
Oct 1 10:32:51 INFO Setting up TLS certificate logger=setup
Oct 1 10:32:51 INFO Creating localbuild resource logger=setup
Oct 1 10:32:51 INFO Starting EventSource controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository source=kind source: *v1alpha1.GitRepository
Oct 1 10:32:51 INFO Starting Controller controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository
Oct 1 10:32:51 INFO Starting EventSource controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild source=kind source: *v1alpha1.Localbuild
Oct 1 10:32:51 INFO Starting Controller controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild
Oct 1 10:32:51 INFO Starting EventSource controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage source=kind source: *v1alpha1.CustomPackage
Oct 1 10:32:51 INFO Starting Controller controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage
Oct 1 10:32:51 INFO Starting workers controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild worker count=1
Oct 1 10:32:51 INFO Starting workers controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage worker count=1
Oct 1 10:32:51 INFO Starting workers controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository worker count=1
Oct 1 10:32:54 INFO Waiting for Deployment my-gitea to become ready controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=6fc396d4-e0d5-4c80-aaee-20c1bbffea54
Oct 1 10:32:54 INFO Waiting for Deployment ingress-nginx-controller to become ready controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=6fc396d4-e0d5-4c80-aaee-20c1bbffea54
Oct 1 10:33:24 INFO Waiting for Deployment my-gitea to become ready controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=6fc396d4-e0d5-4c80-aaee-20c1bbffea54
Oct 1 10:33:24 INFO Waiting for Deployment ingress-nginx-controller to become ready controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=6fc396d4-e0d5-4c80-aaee-20c1bbffea54
Oct 1 10:33:54 INFO Waiting for Deployment my-gitea to become ready controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=6fc396d4-e0d5-4c80-aaee-20c1bbffea54
Oct 1 10:34:24 INFO installing bootstrap apps to ArgoCD controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=6fc396d4-e0d5-4c80-aaee-20c1bbffea54
Oct 1 10:34:24 INFO expected annotation, cnoe.io/last-observed-cli-start-time, not found controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=6fc396d4-e0d5-4c80-aaee-20c1bbffea54
Oct 1 10:34:24 INFO Checking if we should shutdown controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=6fc396d4-e0d5-4c80-aaee-20c1bbffea54
Oct 1 10:34:25 INFO installing bootstrap apps to ArgoCD controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=0667fa85-af1c-403f-bcd9-16ff8f2fad7e
Oct 1 10:34:25 INFO expected annotation, cnoe.io/last-observed-cli-start-time, not found controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=0667fa85-af1c-403f-bcd9-16ff8f2fad7e
Oct 1 10:34:25 INFO Checking if we should shutdown controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=0667fa85-af1c-403f-bcd9-16ff8f2fad7e
Oct 1 10:34:40 INFO installing bootstrap apps to ArgoCD controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=ec720aeb-02cd-4974-a991-cf2f19ce8536
Oct 1 10:34:40 INFO Checking if we should shutdown controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=ec720aeb-02cd-4974-a991-cf2f19ce8536
Oct 1 10:34:40 INFO Shutting Down controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=ec720aeb-02cd-4974-a991-cf2f19ce8536
Oct 1 10:34:40 INFO Stopping and waiting for non leader election runnables
Oct 1 10:34:40 INFO Stopping and waiting for leader election runnables
Oct 1 10:34:40 INFO Shutdown signal received, waiting for all workers to finish controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository
Oct 1 10:34:40 INFO Shutdown signal received, waiting for all workers to finish controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage
Oct 1 10:34:40 INFO All workers finished controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage
Oct 1 10:34:40 INFO Shutdown signal received, waiting for all workers to finish controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild
Oct 1 10:34:40 INFO All workers finished controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild
Oct 1 10:34:40 INFO All workers finished controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository
Oct 1 10:34:40 INFO Stopping and waiting for caches
Oct 1 10:34:40 INFO Stopping and waiting for webhooks
Oct 1 10:34:40 INFO Stopping and waiting for HTTP servers
Oct 1 10:34:40 INFO Wait completed, proceeding to shutdown the manager
########################### Finished Creating IDP Successfully! ############################
Can Access ArgoCD at https://cnoe.localtest.me:8443/argocd
Username: admin
Password can be retrieved by running: idpbuilder get secrets -p argocd
When running idpbuilder ‘barely’ (without package option) you get the ‘core applications’ deployed in your cluster:
stl@ubuntu-vpn:~/git/mms/ipceicis-developerframework$ k get applications -A
NAMESPACE NAME SYNC STATUS HEALTH STATUS
argocd argocd Synced Healthy
argocd gitea Synced Healthy
argocd nginx Synced Healthy
Open ArgoCD locally:
https://cnoe.localtest.me:8443/argocd
Next find the provided credentials for ArgoCD (here: argocd-initial-admin-secret):
stl@ubuntu-vpn:~/git/mms/idpbuilder$ ib get secrets
---------------------------
Name: argocd-initial-admin-secret
Namespace: argocd
Data:
password : 2MoMeW30wSC9EraF
username : admin
---------------------------
Name: gitea-credential
Namespace: gitea
Data:
password : LI$T?o>N{-<|{^dm$eTg*gni1(2:Y0@q344yqQIS
username : giteaAdmin
In ArgoCD you will see the deployed three applications of the core package:
CNOE provides example packages in https://github.com/cnoe-io/stacks.git. Having cloned this repo you can locally refer to theses packages:
stl@ubuntu-vpn:~/git/mms/cnoe-stacks$ git remote -v
origin https://github.com/cnoe-io/stacks.git (fetch)
origin https://github.com/cnoe-io/stacks.git (push)
stl@ubuntu-vpn:~/git/mms/cnoe-stacks$ ls -al
total 64
drwxr-xr-x 12 stl stl 4096 Sep 28 13:55 .
drwxr-xr-x 26 stl stl 4096 Sep 30 11:53 ..
drwxr-xr-x 8 stl stl 4096 Sep 28 13:56 .git
drwxr-xr-x 4 stl stl 4096 Jul 29 10:57 .github
-rw-r--r-- 1 stl stl 11341 Sep 28 09:12 LICENSE
-rw-r--r-- 1 stl stl 1079 Sep 28 13:55 README.md
drwxr-xr-x 4 stl stl 4096 Jul 29 10:57 basic
drwxr-xr-x 4 stl stl 4096 Sep 14 15:54 crossplane-integrations
drwxr-xr-x 3 stl stl 4096 Aug 13 14:52 dapr-integration
drwxr-xr-x 3 stl stl 4096 Sep 14 15:54 jupyterhub
drwxr-xr-x 6 stl stl 4096 Aug 16 14:36 local-backup
drwxr-xr-x 3 stl stl 4096 Aug 16 14:36 localstack-integration
drwxr-xr-x 8 stl stl 4096 Sep 28 13:02 ref-implementation
drwxr-xr-x 2 stl stl 4096 Aug 16 14:36 terraform-integrations
stl@ubuntu-vpn:~/git/mms/cnoe-stacks$ ls -al basic/
total 20
drwxr-xr-x 4 stl stl 4096 Jul 29 10:57 .
drwxr-xr-x 12 stl stl 4096 Sep 28 13:55 ..
-rw-r--r-- 1 stl stl 632 Jul 29 10:57 README.md
drwxr-xr-x 3 stl stl 4096 Jul 29 10:57 package1
drwxr-xr-x 2 stl stl 4096 Jul 29 10:57 package2
stl@ubuntu-vpn:~/git/mms/cnoe-stacks$ ls -al basic/package1
total 16
drwxr-xr-x 3 stl stl 4096 Jul 29 10:57 .
drwxr-xr-x 4 stl stl 4096 Jul 29 10:57 ..
-rw-r--r-- 1 stl stl 655 Jul 29 10:57 app.yaml
drwxr-xr-x 2 stl stl 4096 Jul 29 10:57 manifests
stl@ubuntu-vpn:~/git/mms/cnoe-stacks$ ls -al basic/package2
total 16
drwxr-xr-x 2 stl stl 4096 Jul 29 10:57 .
drwxr-xr-x 4 stl stl 4096 Jul 29 10:57 ..
-rw-r--r-- 1 stl stl 498 Jul 29 10:57 app.yaml
-rw-r--r-- 1 stl stl 500 Jul 29 10:57 app2.yaml
Now we run idpbuilder the second time with -p basic/package1
stl@ubuntu-vpn:~/git/mms/cnoe-stacks$ ib create --use-path-routing -p basic/package1
Oct 1 12:09:27 INFO Creating kind cluster logger=setup
Oct 1 12:09:27 INFO Runtime detected logger=setup provider=docker
Oct 1 12:09:27 INFO Cluster already exists logger=setup cluster=localdev
Oct 1 12:09:28 INFO Adding CRDs to the cluster logger=setup
Oct 1 12:09:28 INFO Setting up CoreDNS logger=setup
Oct 1 12:09:28 INFO Setting up TLS certificate logger=setup
Oct 1 12:09:28 INFO Creating localbuild resource logger=setup
Oct 1 12:09:28 INFO Starting EventSource controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild source=kind source: *v1alpha1.Localbuild
Oct 1 12:09:28 INFO Starting Controller controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild
Oct 1 12:09:28 INFO Starting EventSource controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage source=kind source: *v1alpha1.CustomPackage
Oct 1 12:09:28 INFO Starting Controller controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage
Oct 1 12:09:28 INFO Starting EventSource controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository source=kind source: *v1alpha1.GitRepository
Oct 1 12:09:28 INFO Starting Controller controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository
Oct 1 12:09:28 INFO Starting workers controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild worker count=1
Oct 1 12:09:28 INFO Starting workers controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository worker count=1
Oct 1 12:09:28 INFO Starting workers controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage worker count=1
Oct 1 12:09:29 INFO installing bootstrap apps to ArgoCD controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=0ed7ccc2-dec7-4ab8-909c-791a7d1b67a8
Oct 1 12:09:29 INFO unknown field "status.history[0].initiatedBy" logger=KubeAPIWarningLogger
Oct 1 12:09:29 INFO Checking if we should shutdown controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=0ed7ccc2-dec7-4ab8-909c-791a7d1b67a8
Oct 1 12:09:29 ERROR failed updating repo status controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage name=app-my-app namespace=idpbuilder-localdev namespace=idpbuilder-localdev name=app-my-app reconcileID=f9873560-5dcd-4e59-b6f7-ce5d1029ef3d err=Operation cannot be fulfilled on custompackages.idpbuilder.cnoe.io "app-my-app": the object has been modified; please apply your changes to the latest version and try again
Oct 1 12:09:29 ERROR Reconciler error controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage name=app-my-app namespace=idpbuilder-localdev namespace=idpbuilder-localdev name=app-my-app reconcileID=f9873560-5dcd-4e59-b6f7-ce5d1029ef3d err=updating argocd application object my-app: Operation cannot be fulfilled on applications.argoproj.io "my-app": the object has been modified; please apply your changes to the latest version and try again
Oct 1 12:09:31 INFO installing bootstrap apps to ArgoCD controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=531cc2d4-6250-493a-aca8-fecf048a608d
Oct 1 12:09:31 INFO Checking if we should shutdown controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=531cc2d4-6250-493a-aca8-fecf048a608d
Oct 1 12:09:44 INFO installing bootstrap apps to ArgoCD controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=022b9813-8708-4f4e-90d7-38f1e114c46f
Oct 1 12:09:44 INFO Checking if we should shutdown controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=022b9813-8708-4f4e-90d7-38f1e114c46f
Oct 1 12:10:00 INFO installing bootstrap apps to ArgoCD controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=79a85c21-42c1-41ec-ad03-2bb77aeae027
Oct 1 12:10:00 INFO Checking if we should shutdown controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=79a85c21-42c1-41ec-ad03-2bb77aeae027
Oct 1 12:10:00 INFO Shutting Down controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild name=localdev name=localdev reconcileID=79a85c21-42c1-41ec-ad03-2bb77aeae027
Oct 1 12:10:00 INFO Stopping and waiting for non leader election runnables
Oct 1 12:10:00 INFO Stopping and waiting for leader election runnables
Oct 1 12:10:00 INFO Shutdown signal received, waiting for all workers to finish controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage
Oct 1 12:10:00 INFO Shutdown signal received, waiting for all workers to finish controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository
Oct 1 12:10:00 INFO All workers finished controller=custompackage controllerGroup=idpbuilder.cnoe.io controllerKind=CustomPackage
Oct 1 12:10:00 INFO Shutdown signal received, waiting for all workers to finish controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild
Oct 1 12:10:00 INFO All workers finished controller=localbuild controllerGroup=idpbuilder.cnoe.io controllerKind=Localbuild
Oct 1 12:10:00 INFO All workers finished controller=gitrepository controllerGroup=idpbuilder.cnoe.io controllerKind=GitRepository
Oct 1 12:10:00 INFO Stopping and waiting for caches
Oct 1 12:10:00 INFO Stopping and waiting for webhooks
Oct 1 12:10:00 INFO Stopping and waiting for HTTP servers
Oct 1 12:10:00 INFO Wait completed, proceeding to shutdown the manager
########################### Finished Creating IDP Successfully! ############################
Can Access ArgoCD at https://cnoe.localtest.me:8443/argocd
Username: admin
Password can be retrieved by running: idpbuilder get secrets -p argocd
Now we have additionally the ‘my-app’ deployed in the cluster:
stl@ubuntu-vpn:~$ k get applications -A
NAMESPACE NAME SYNC STATUS HEALTH STATUS
argocd argocd Synced Healthy
argocd gitea Synced Healthy
argocd my-app Synced Healthy
argocd nginx Synced Healthy
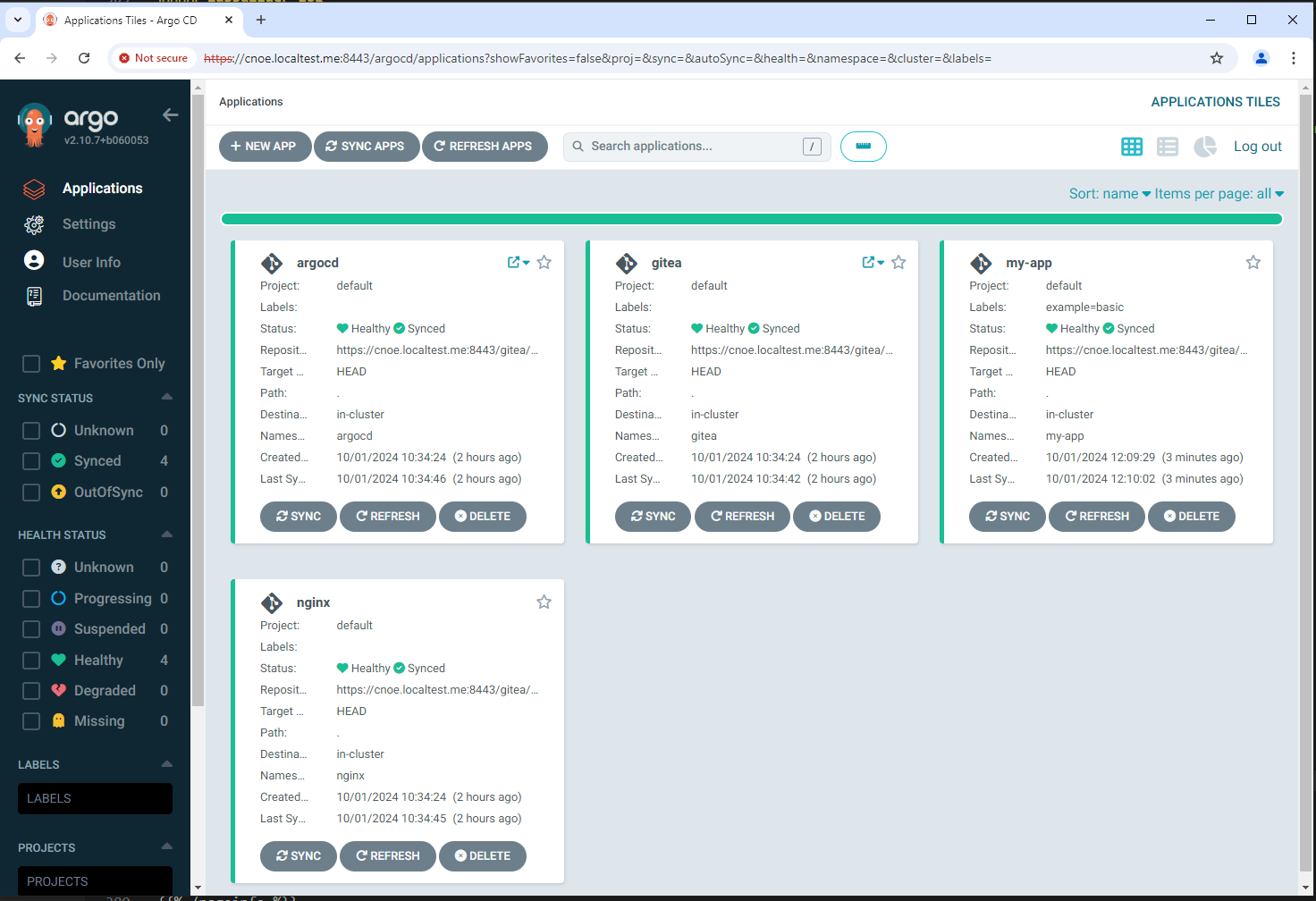
We finally append the so called ‘reference-implementation’, which provides a real basic IDP:
stl@ubuntu-vpn:~/git/mms/cnoe-stacks$ ib create --use-path-routing -p ref-implementation
stl@ubuntu-vpn:~$ k get applications -A
NAMESPACE NAME SYNC STATUS HEALTH STATUS
argocd argo-workflows Synced Healthy
argocd argocd Synced Healthy
argocd backstage Synced Healthy
argocd included-backstage-templates Synced Healthy
argocd external-secrets Synced Healthy
argocd gitea Synced Healthy
argocd keycloak Synced Healthy
argocd metric-server Synced Healthy
argocd my-app Synced Healthy
argocd nginx Synced Healthy
argocd spark-operator Synced Healthy
ArgoCD shows all provissioned applications:
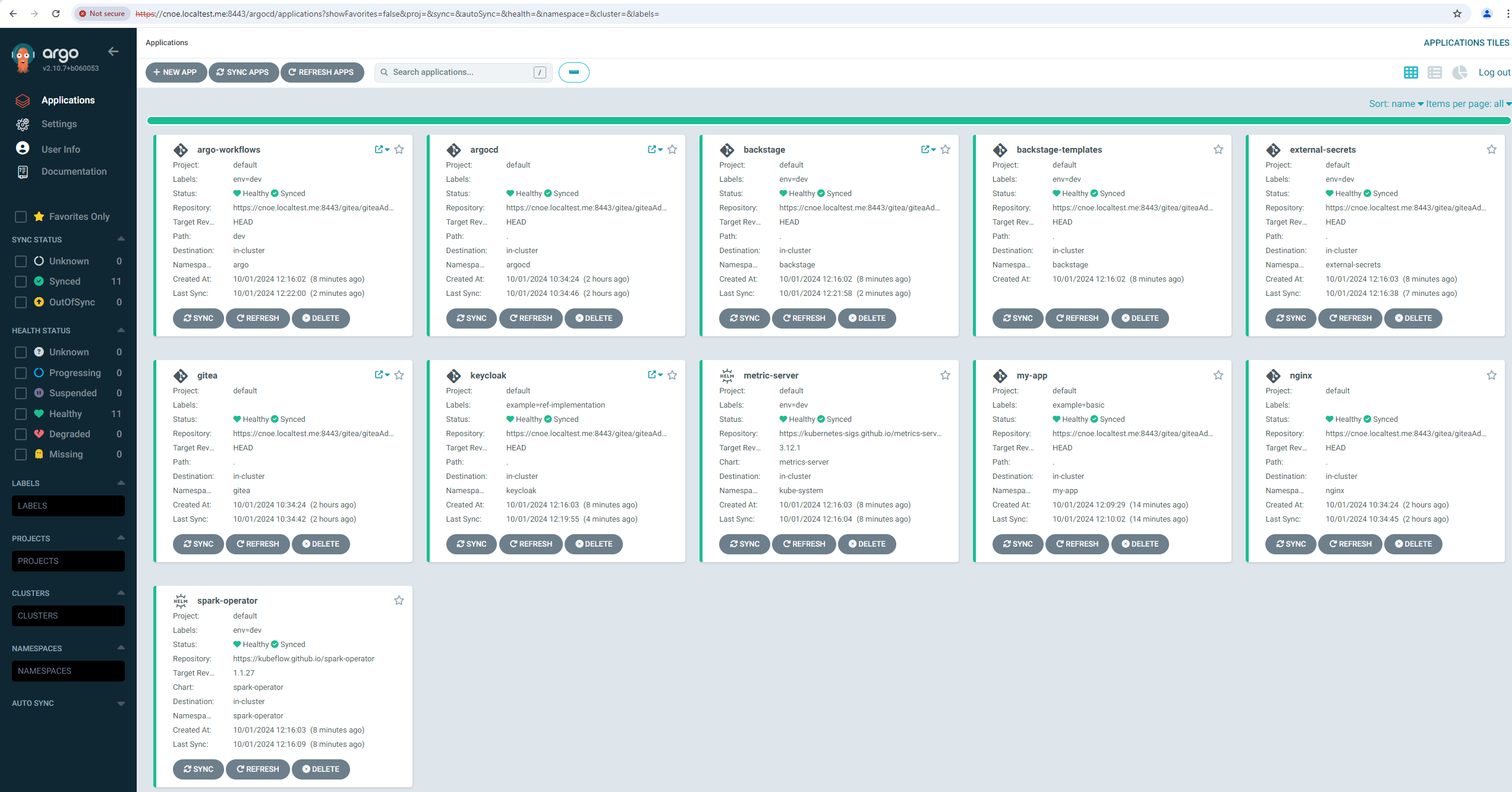
In our cluster there is also keycloak as IAM provisioned.
Login into Keycloak with ‘cnoe-admin’ and the KEYCLOAK_ADMIN_PASSWORD.
These credentails are defined in the package:
stl@ubuntu-vpn:~/git/mms/cnoe-stacks$ cat ref-implementation/keycloak/manifests/keycloak-config.yaml | grep -i admin
group-admin-payload.json: |
{"name":"admin"}
"/admin"
ADMIN_PASSWORD=$(cat /var/secrets/KEYCLOAK_ADMIN_PASSWORD)
--data-urlencode "username=cnoe-admin" \
--data-urlencode "password=${ADMIN_PASSWORD}" \
stl@ubuntu-vpn:~/git/mms/cnoe-stacks$ ib get secrets
---------------------------
Name: argocd-initial-admin-secret
Namespace: argocd
Data:
password : 2MoMeW30wSC9EraF
username : admin
---------------------------
Name: gitea-credential
Namespace: gitea
Data:
password : LI$T?o>N{-<|{^dm$eTg*gni1(2:Y0@q344yqQIS
username : giteaAdmin
---------------------------
Name: keycloak-config
Namespace: keycloak
Data:
KC_DB_PASSWORD : k3-1kgxxd/X2Cw//pX-uKMsmgWogEz5YGnb5
KC_DB_USERNAME : keycloak
KEYCLOAK_ADMIN_PASSWORD : zMSjv5eA0l/+0-MDAaaNe+rHRMrB2q0NssP-
POSTGRES_DB : keycloak
POSTGRES_PASSWORD : k3-1kgxxd/X2Cw//pX-uKMsmgWogEz5YGnb5
POSTGRES_USER : keycloak
USER_PASSWORD : Kd+0+/BqPRAvnLPZO-L2o/6DoBrzUeMsr29U
As Backstage login you either can use the ‘user1’ with USER_PASSWORD : Kd+0+/BqPRAvnLPZO-L2o/6DoBrzUeMsr29U or you create a new user in keycloak
We create user ‘ipcei’ and also set a password (in tab ‘Credentials’):
Now we can log into backstage (rember: you could have already existing usr ‘user1’):
and see the basic setup of the Backstage portal:
Now we want to use the Backstage portal as a developer. We create in Backstage our own platform based activity by using the golden path template ‘Basic Deployment:
When we run it, we see ‘golden path activities’
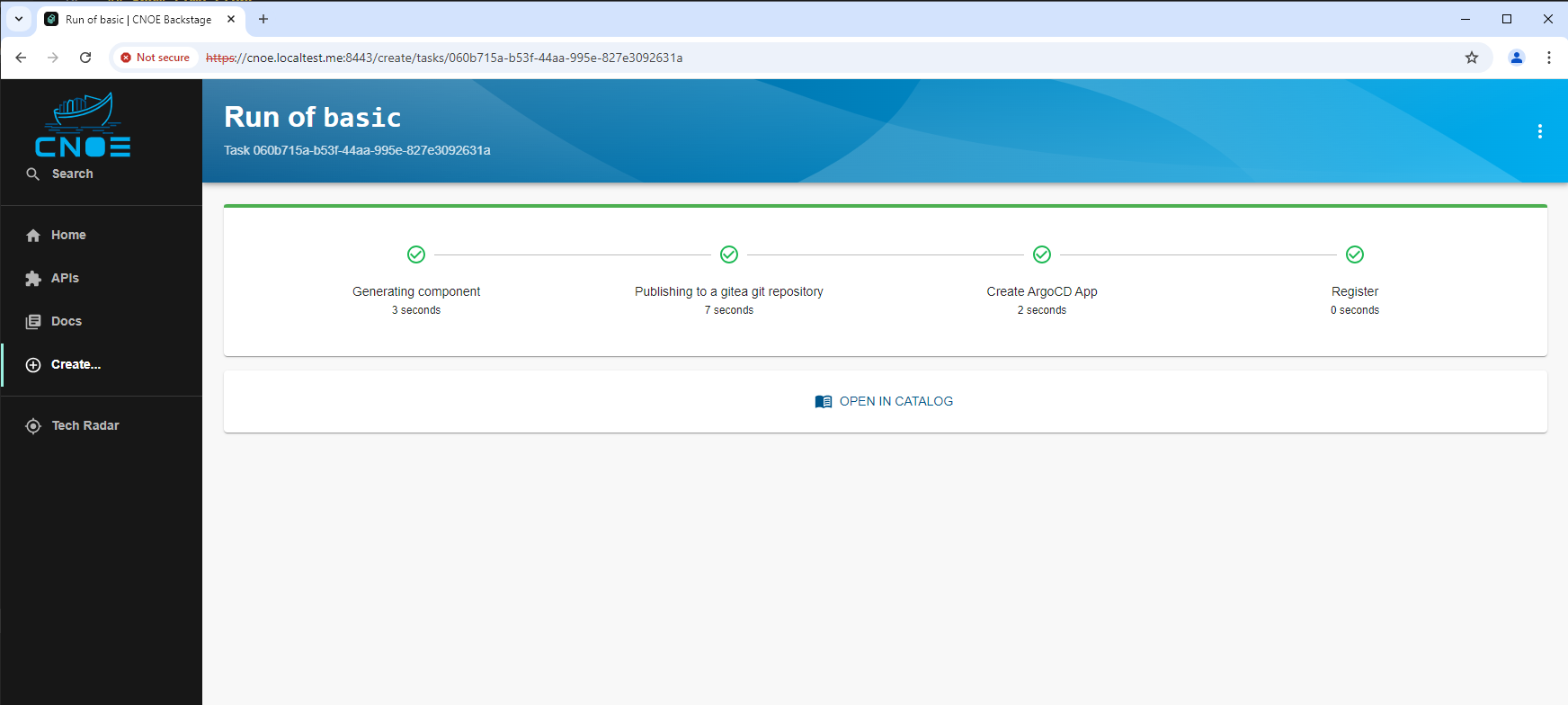
which finally result in a new catalogue entry:
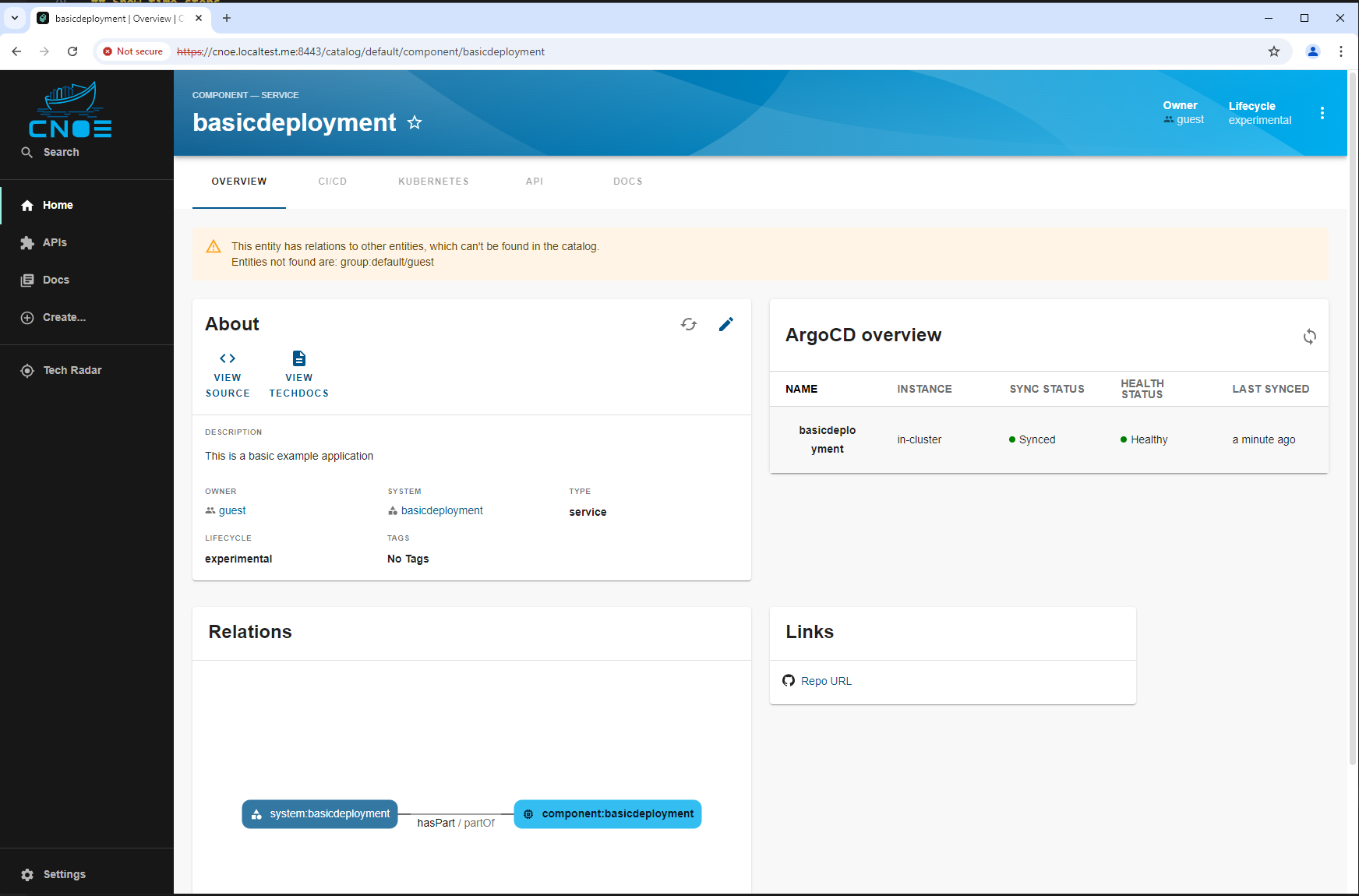
When we follow the ‘view source’ link we are directly linked to the git repo of our newly created application:
Check it out by cloning into a local git repo (watch the GIT_SSL_NO_VERIFY=true env setting):
stl@ubuntu-vpn:~/git/mms/idp-temporary$ GIT_SSL_NO_VERIFY=true git clone https://cnoe.localtest.me:8443/gitea/giteaAdmin/basicdeployment.git
Cloning into 'basicdeployment'...
remote: Enumerating objects: 10, done.
remote: Counting objects: 100% (10/10), done.
remote: Compressing objects: 100% (8/8), done.
remote: Total 10 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
Receiving objects: 100% (10/10), 47.62 KiB | 23.81 MiB/s, done.
stl@ubuntu-vpn:~/git/mms/idp-temporary$ cd basicdeployment/
stl@ubuntu-vpn:~/git/mms/idp-temporary/basicdeployment$ ll
total 24
drwxr-xr-x 5 stl stl 4096 Oct 1 13:00 ./
drwxr-xr-x 4 stl stl 4096 Oct 1 13:00 ../
drwxr-xr-x 8 stl stl 4096 Oct 1 13:00 .git/
-rw-r--r-- 1 stl stl 928 Oct 1 13:00 catalog-info.yaml
drwxr-xr-x 3 stl stl 4096 Oct 1 13:00 docs/
drwxr-xr-x 2 stl stl 4096 Oct 1 13:00 manifests/
Change some things, like the decription and the replicas:
Push your changes, use the giteaAdmin user to authenticate:
stl@ubuntu-vpn:~/git/mms/idp-temporary/basicdeployment$ ib get secrets
---------------------------
Name: argocd-initial-admin-secret
Namespace: argocd
Data:
password : 2MoMeW30wSC9EraF
username : admin
---------------------------
Name: gitea-credential
Namespace: gitea
Data:
password : LI$T?o>N{-<|{^dm$eTg*gni1(2:Y0@q344yqQIS
username : giteaAdmin
---------------------------
Name: keycloak-config
Namespace: keycloak
Data:
KC_DB_PASSWORD : k3-1kgxxd/X2Cw//pX-uKMsmgWogEz5YGnb5
KC_DB_USERNAME : keycloak
KEYCLOAK_ADMIN_PASSWORD : zMSjv5eA0l/+0-MDAaaNe+rHRMrB2q0NssP-
POSTGRES_DB : keycloak
POSTGRES_PASSWORD : k3-1kgxxd/X2Cw//pX-uKMsmgWogEz5YGnb5
POSTGRES_USER : keycloak
USER_PASSWORD : Kd+0+/BqPRAvnLPZO-L2o/6DoBrzUeMsr29U
stl@ubuntu-vpn:~/git/mms/idp-temporary/basicdeployment$ GIT_SSL_NO_VERIFY=true git push
Username for 'https://cnoe.localtest.me:8443': giteaAdmin
Password for 'https://giteaAdmin@cnoe.localtest.me:8443':
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 8 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 382 bytes | 382.00 KiB/s, done.
Total 3 (delta 1), reused 0 (delta 0), pack-reused 0
remote: . Processing 1 references
remote: Processed 1 references in total
To https://cnoe.localtest.me:8443/gitea/giteaAdmin/basicdeployment.git
69244d6..1269617 main -> main
Next wait a bit until Gitops does its magic and our ‘wanted’ state in the repo gets automatically deployed to the ‘production’ cluster:

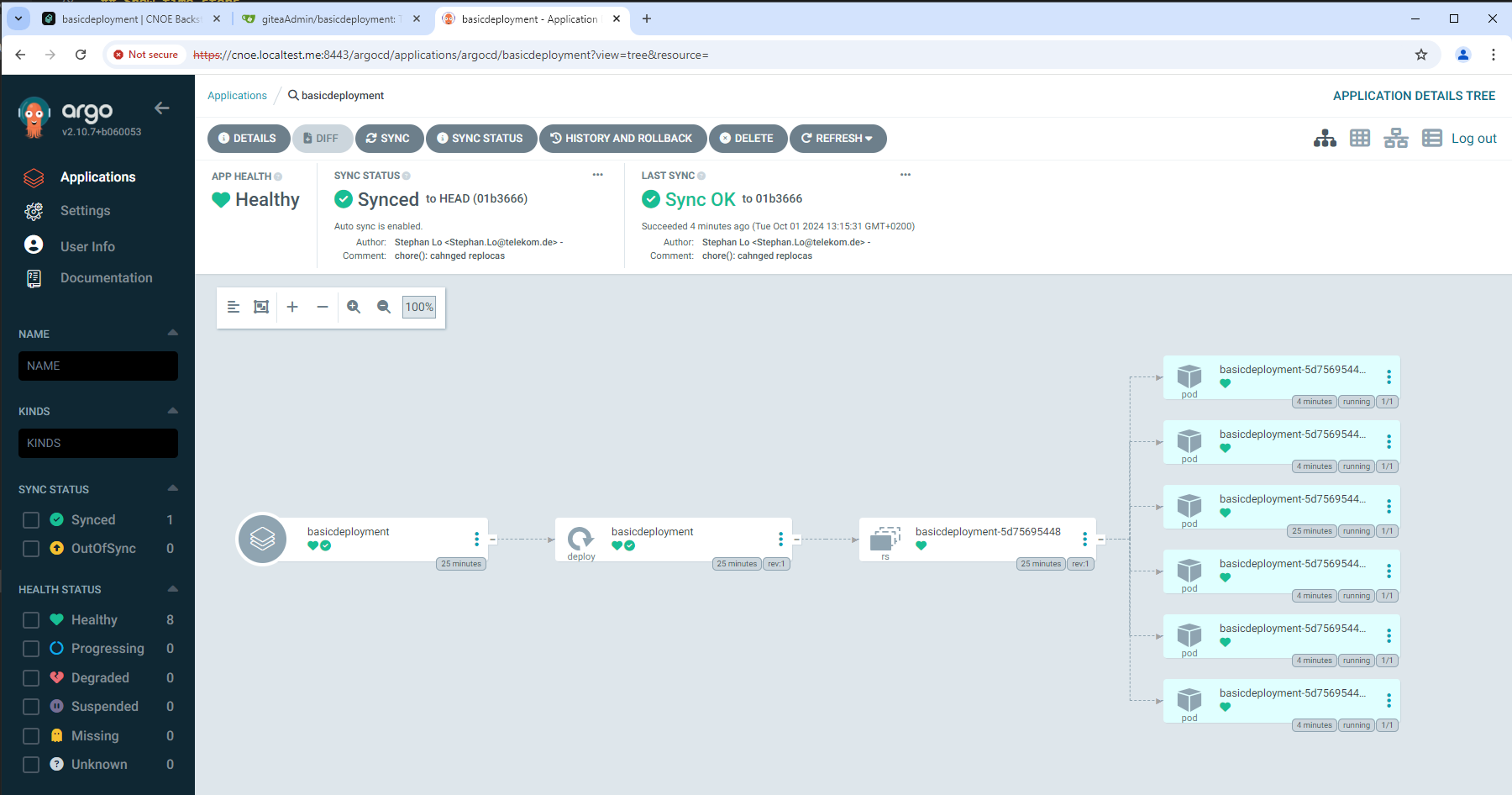
The showtime of CNOE high level behaviour and usage scenarios is now finished. We setup an initial IDP and used a backstage golden path to init and deploy a simple application.
Last not least we want to sum up the whole way from Devops to ‘Frameworking’ (is this the correct wording???)
In the project ‘Edge Developer Framework’ we start with DevOps, set platforms on top to automate golden paths, and finally set ‘frameworks’ (aka Orchestrators’) on top to have declarative,automated and reconcilable platforms.
We come along from a quite well known, but already complex discipline called ‘Platform Engineering’, which is the next level devops. On top of these two domains we now have ‘Framework Engineering’, i.e. buildung dynamic, orchestrated and reconciling platforms:
| Classic Platform engineering | New: Framework Orchestration on top of Platforms | Your job: Framework Engineer |
|---|---|---|
 |  |  |
So always keep in mind that as as ‘Framework Engineer’ you
The following diamond is illustrating this: on top is you, on the bottom is our baseline ‘DevOps’

// how to create/export c4 images: // see also https://likec4.dev/tooling/cli/
docker run -it –rm –name likec4 –user node -v $PWD:/app node bash npm install likec4 exit
docker commit likec4 likec4 docker run -it –rm –user node -v $PWD:/app -p 5173:5173 likec4 bash
// as root npx playwright install-deps npx playwright install
npm install likec4
// render node@e20899c8046f:/app/content/en/docs/project/onboarding$ ./node_modules/.bin/likec4 export png -o ./images .
In order to be able to do useful work, we do need a number of applications right away. We’re deploying these manually so we have the necessary basis for our work. Once the framework has been developed far enough, we will deploy this infrastructure with the framework itself.
We are using Velero for backup and restore of the deployed applications.
To manage a Velero install in a cluster, you need to have Velero command line tools installed locally. Please follow the instructions for Basic Install.
Installing and configuring Velero for a cluster can be accomplished with the CLI.
credentials.ini.[default]
aws_access_key_id = "Access Key Value"
aws_secret_access_key = "Secret Key Value"
velero install \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.2.1 \
--bucket osc-backup \
--secret-file ./credentials.ini \
--use-volume-snapshots=false \
--use-node-agent=true \
--backup-location-config region=minio,s3ForcePathStyle="true",s3Url=https://obs.eu-de.otc.t-systems.com
credentials.ini, it is not needed anymore (a secret has been created in the cluster).velero schedule create devfw-bootstrap --schedule="23 */2 * * *" "--include-namespaces=forgejo"
You can now use Velero to create backups, restore them, or perform other operations. Please refer to the Velero Documentation.
To list all currently available backups:
velero backup get
We are using the S3-compatible Open Telekom Cloud Object Storage service to make available some storage for the backups. We picked OTC specifically because we’re not using it for anything else, so no matter what catastrophy we create in Open Sovereign Cloud, the backups should be safe.
The access key is a CSV file with the Access Key and the Secret Key listed in the second line.
Our first architectural blue print for the IPCEI-CIS Developer Framework derives from Humanitecs Reference Architecture, see links in Blog
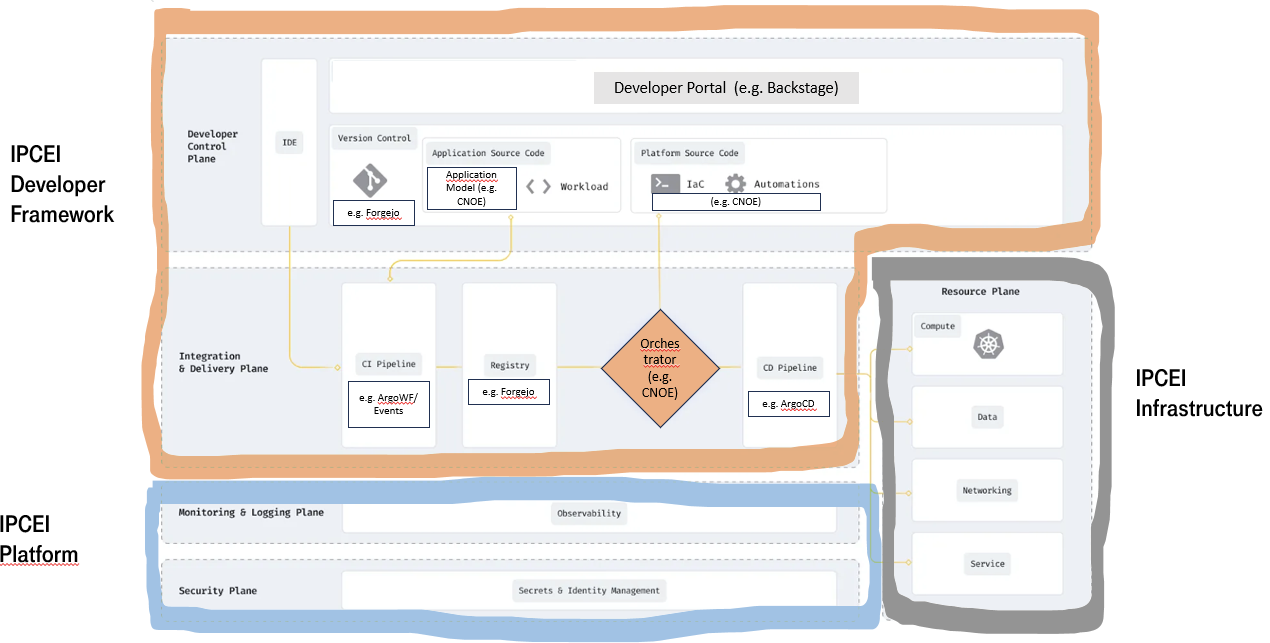
(sources see in ./ressources/architecture-c4)
How to use: install C4lite VSC exension and/or C4lite cli - then open *.c4 files in ./ressources/architecture-c4
First system landscape C4 model:
https://confluence.telekom-mms.com/display/IPCEICIS/Architecture
Next Steps: (Vorschlag: in den nächsten 2 Wochen)
This page is WiP (23.8.2024).
Continued discussion on 29th Aug 24
- idea: Top down mit SAFe, Value Streams
- paralell dazu bottom up (die zB aus den technisch/operativen Tätigkeietn entstehen)
- Scrum Master?
- Claim: Self Service im Onboarding (BTW, genau das Versprechen vom Developer Framework)
- Org-Struktur: Scrum of Scrum (?), max. 8,9 Menschen
Stefan and Stephan try to solve the mission ‘wir wollen losmachen’.
Solution Idea:
We discovered three streams in the first project steps (see also blog):
#
## Stream 'Fundamentals'
### [Platform-Definition](./fundamentals/platform-definition/)
### [CI/CD Definition](./fundamentals/cicd-definition/)
## Stream 'POC'
### [CNOE](./pocs/cnoe/)
### [Kratix](./pocs/kratix/)
### [SIA Asset](./pocs/sia-asset/)
### Backstage
### Telemetry
## Stream 'Deployment'
### [Forgejo](./deployment/forgejo/)
Bevor eine Aufgabe umgesetzt wird, muss ein Design vorhanden sein.
Bezüglich der ‘Bebauung’ von Plaztform-Komponenten gilt für das Design:
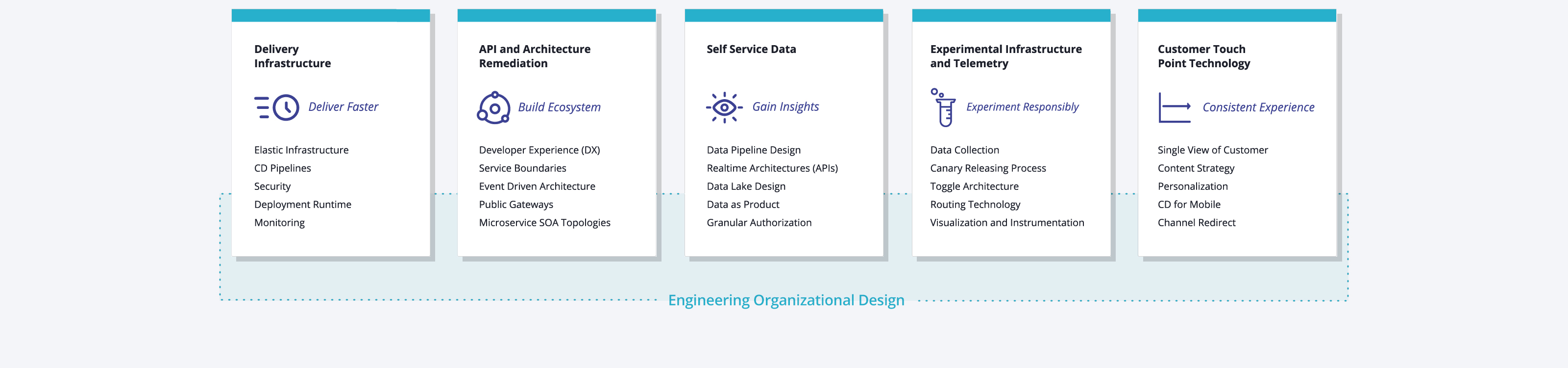
Das theoretische Fundament unserer Plattform-Architektur soll begründet und weitere wesentliche Erfahrungen anderer Player durch Recherche erhoben werden, so dass unser aktuelles Zielbild abgesichert ist.
Wir starten gerade auf der Bais des Referenzmodells zu Platform-Engineering von Gartner und Huamitec. Es gibt viele weitere Grundlagen und Entwicklungen zu Platform Engineering.
Der Produktionsprozess für Applikationen soll im Kontext von Gitops und Plattformen entworfen und mit einigen Workflowsystemen im Leerlauf implementiert werden.
In Gitops basierten Plattformen (Anm.: wie es zB. CNOE und Humanitec mit ArgoCD sind) trifft das klassische Verständnis von Pipelining mit finalem Pushing des fertigen Builds auf die Target-Plattform nicht mehr zu.
D.h. in diesem fall is Argo CD = Continuous Delivery = Pulling des desired state auf die Target plattform. Eine pipeline hat hier keien Rechte mehr, single source of truth ist das ‘Control-Git’.
D.h. es stellen sich zwei Fragen:
Als designiertes Basis-Tool des Developer Frameworks sollen die Verwendung und die Möglichkeiten von CNOE zur Erweiterung analysiert werden.
CNOE ist das designierte Werkzeug zur Beschreibung und Ausspielung des Developer Frameworks. Dieses Werkzeug gilt es zu erlernen, zu beschreiben und weiterzuentwickeln. Insbesondere der Metacharkter des ‘Software zur Bereitstellung von Bereitstellungssoftware für Software’, d.h. der unterschiedlichen Ebenen für unterschiedliche Use Cases und Akteure soll klar verständlich und dokumentiert werden. Siehe hierzu auch das Webinar von Huamnitec und die Diskussion zu unterschiedlichen Bereitstellungsmethoden eines RedisCaches.
Implementierung eines Golden Paths in einem CNOE/Backstage Stack für das existierende ‘Composable SIA (Semasuite Integrator Asset)’.
Das SIA Asset ist eine Entwicklung des PC DC - es ist eine Composable Application die einen OnlineShop um die Möglichkeit der FAX-Bestellung erweitert. Die Entwicklung begann im Januar 2024 mit einem Team von drei Menschen, davon zwei Nearshore, und hatte die typischen ersten Stufen - erst Applikationscode ohne Integration, dann lokale gemockte Integration, dann lokale echte Integration, dann Integration auf einer Integrationsumgebung, dann Produktion. Jedesmal bei Erklimmung der nächsten Stufe mit Erstellung von individuellem Build und Deploymentcode und Abwägungen, wie aufwändig nachhaltig und wie benutzbar das jeweilige Konstrukt sein sollte. Ein CI/CD gibt es nicht, zu großer Aufwand für so ein kleines Projekt.
Die Erwartung ist, dass so ein Projekt als ‘Golden Path’ abbildbar ist und die Entwicklung enorm bescheunigt.
graph TB
Developer[fa:fa-user developer]
PlatformDeliveryAndControlPlaneIDE[IDE]
subgraph LocalBox["localBox"]
LocalBox.EDF[Platform]
LocalBox.Local[local]
end
subgraph CloudGroup["cloudGroup"]
CloudGroup.Test[test]
CloudGroup.Prod[prod]
end
Developer -. "use preferred IDE as local code editing, building, testing, syncing tool" .-> PlatformDeliveryAndControlPlaneIDE
Developer -. "manage (in Developer Portal)" .-> LocalBox.EDF
PlatformDeliveryAndControlPlaneIDE -. "provide "code"" .-> LocalBox.EDF
LocalBox.EDF -. "provision" .-> LocalBox.Local
LocalBox.EDF -. "provision" .-> CloudGroup.Prod
LocalBox.EDF -. "provision" .-> CloudGroup.TestIst Kratix eine valide Alternative zu CNOE?
Mantra:
- Everything as Code.
- Cloud natively deployable everywhere.
- Ramping up and tearing down oftenly is a no-brainer.
- Especially locally (whereby ’locally’ means ‘under my own control’)
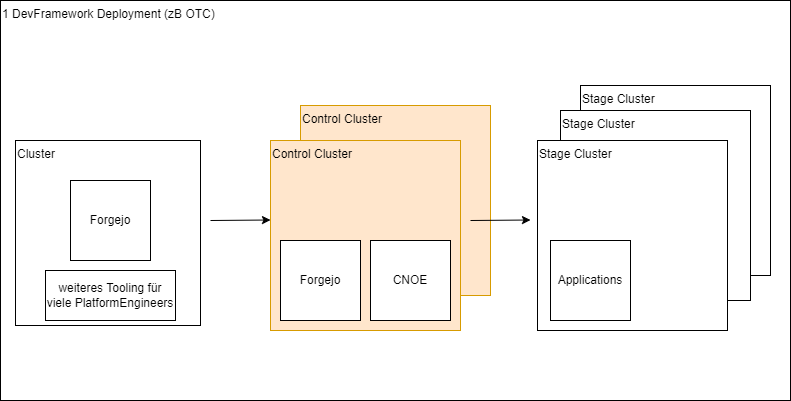
WiP Ich (Stephan) schreibe mal schnell einige Stichworte, was ich so von Stefan gehört habe:
tbd
Presented and approved on tuesday, 26.11.2024 within the team:
The use cases/application lifecycle and deployment flow is drawn here: https://confluence.telekom-mms.com/display/IPCEICIS/Proof+of+Concept+2024
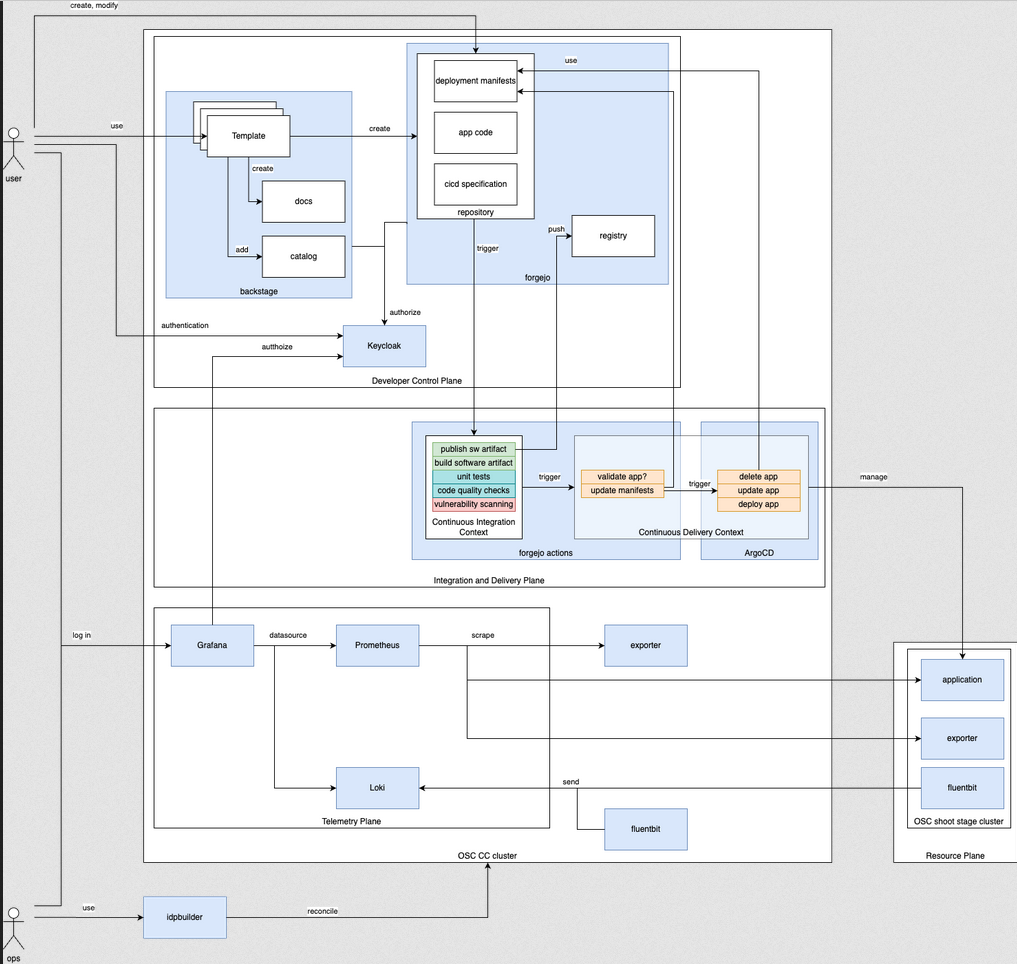
This section is derived from conceptual-onboarding-intro
don’t mix up ‘golden paths’ with pipelines or CI/CD

As Gartner states: “By 2026, 80% of software engineering organizations will establish platform teams as internal providers of reusable services, components and tools for application delivery.”
Here is a small list of companies alrteady using IDPs:
So the goal of platforming is to build a ‘digital platform’ which fits this architecture (Ref. in German):
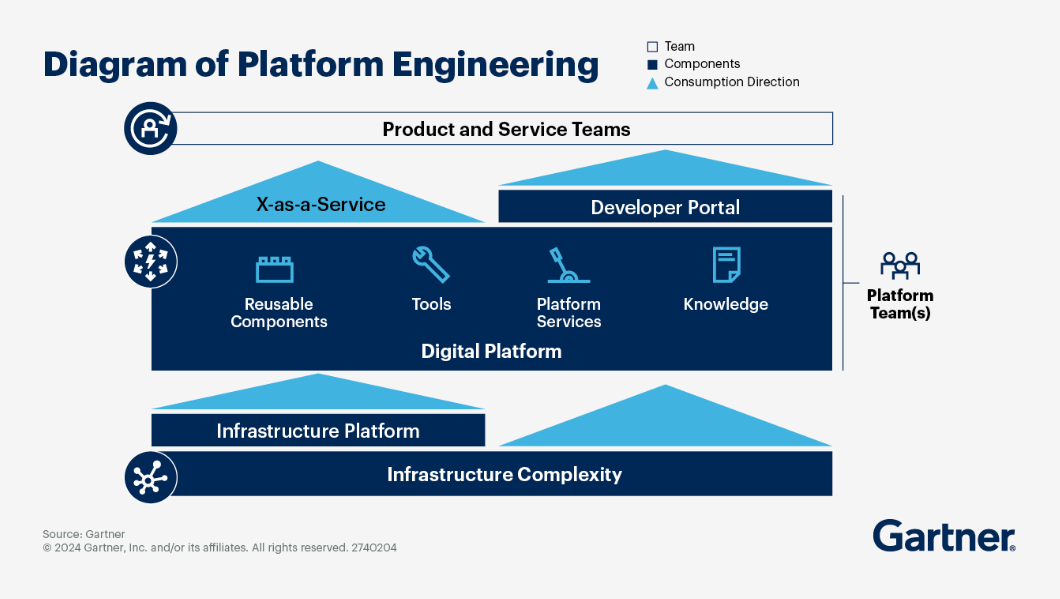
The blue print for such a platform is given by the reference architecture from Humanitec:
Since 2023 this is done by ‘orchestrating’ such platforms. One orchestrator is the CNOE solution, which highly inspired our approach.
In our orchestartion engine we think in ‘stacks’ of ‘packages’ containing platform components.
Sticking together the platforming orchestration concept, the reference architecture and the CNOE stack solution, this is our current running platform minimum viable product.
This will now be presented! Enjoy!
This document describes a proposal to set up a team work structure to primarily get the POC successfully delivered. Later on we will adjust and refine the process to fit for the MVP.
We currently face the following challenges in our process:
A project goal drives us as a team to create valuable product output.
The backlog contains the product specification which instructs us by working in tasks with the help and usage of ressources (like git, 3rd party code and knowledge and so on).
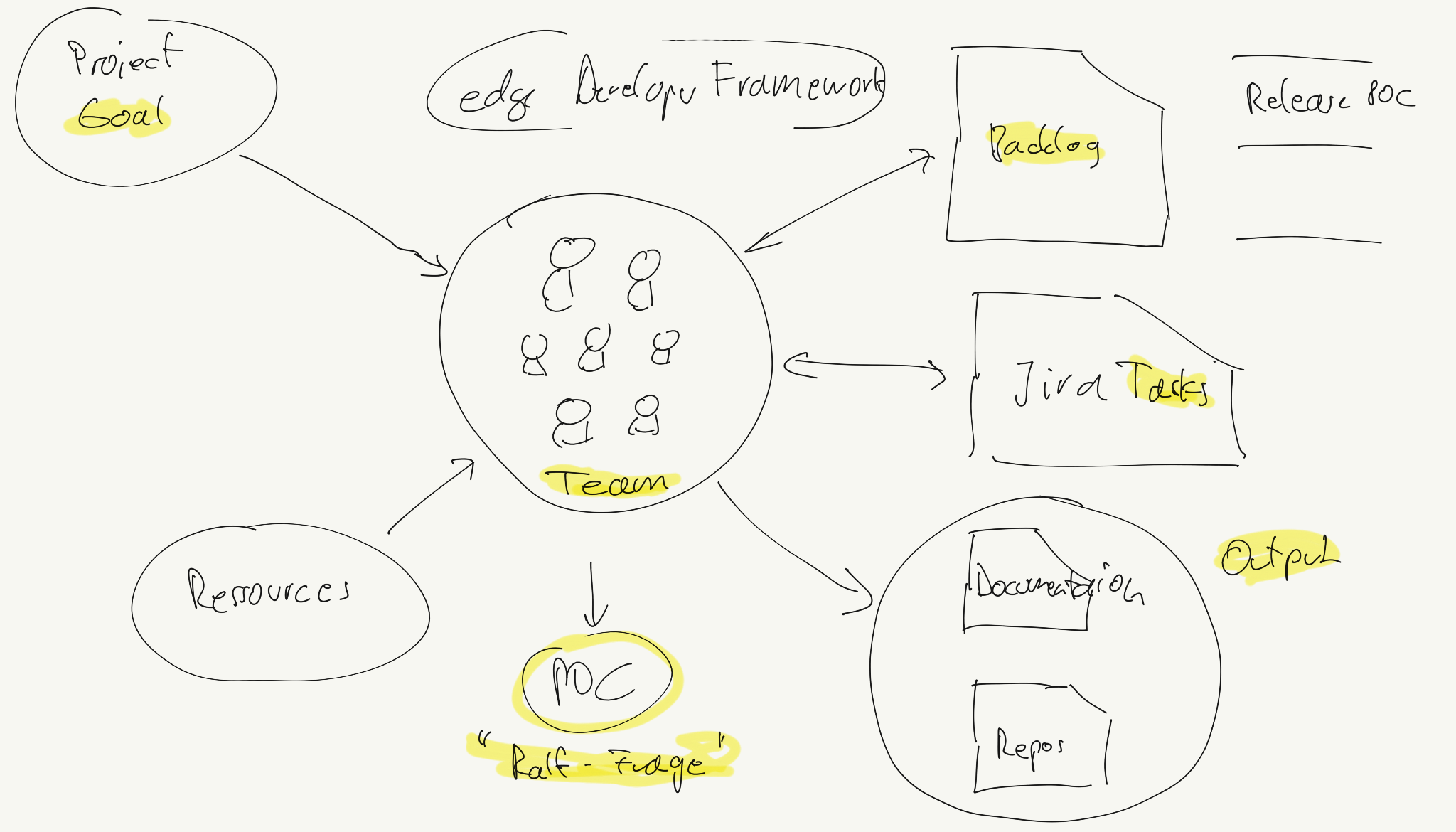
Goal, Backlog, Tasks and Output must be in a well-defined context, such that the team can be productive.
This document has two targets: POC and MVP.
Today is mid november 2024 and we need to package our project results created since july 2024 to deliver the POC product.
Think of the agenda’s goal like this: Imagine Ralf the big sponsor passes by and sees ’edge Developer Framework’ somewhere on your screen. Then he asks: ‘Hey cool, you are one of these famous platform guys?! I always wanted to get a demo how this framework looks like!’
What are you going to show him?
In the following we will look at the work structure proposal, primarily for the POC, but reusable for any other release or the MVP
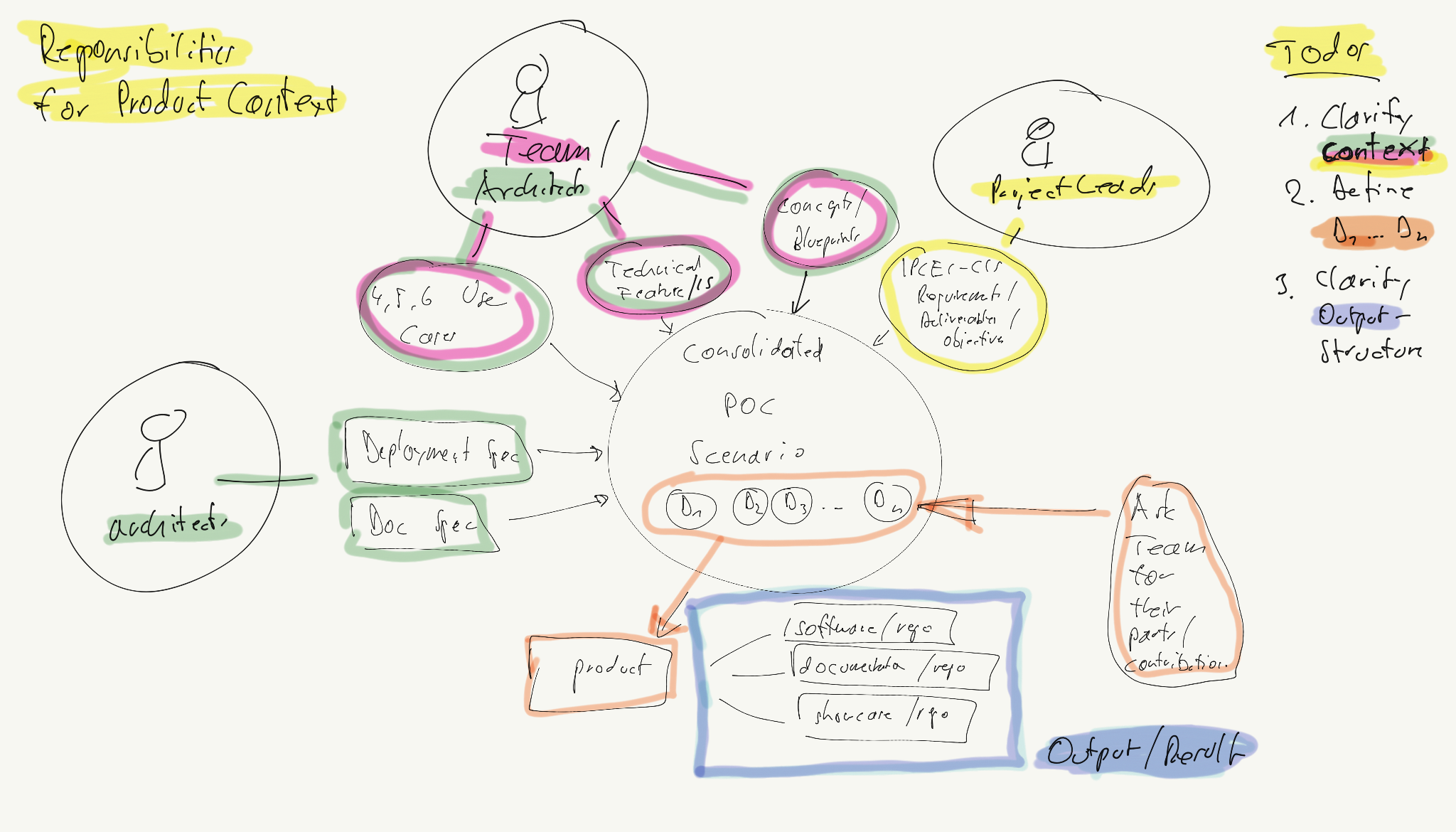
Most important in the process are:
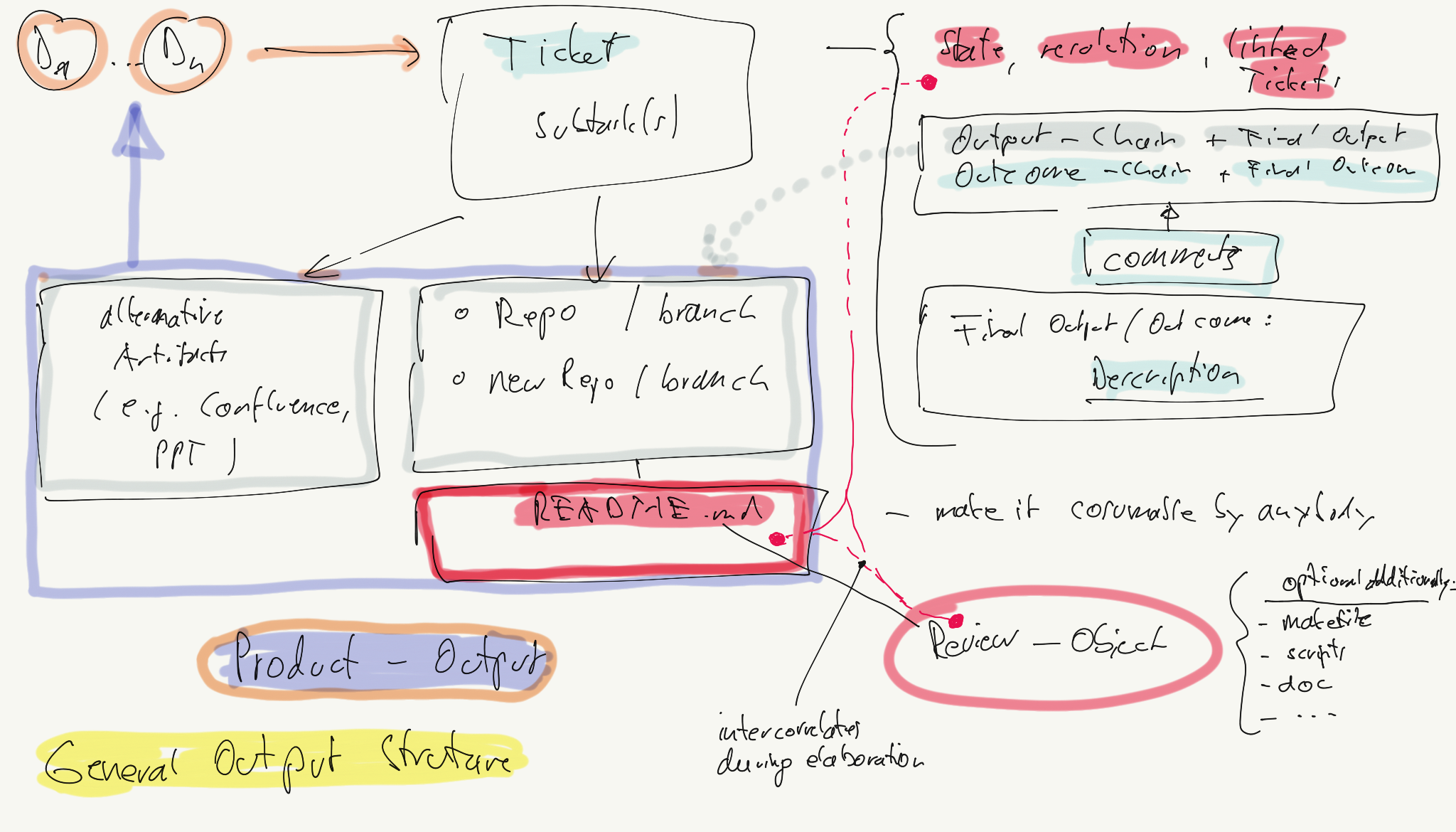
Most important in the POC structure are:
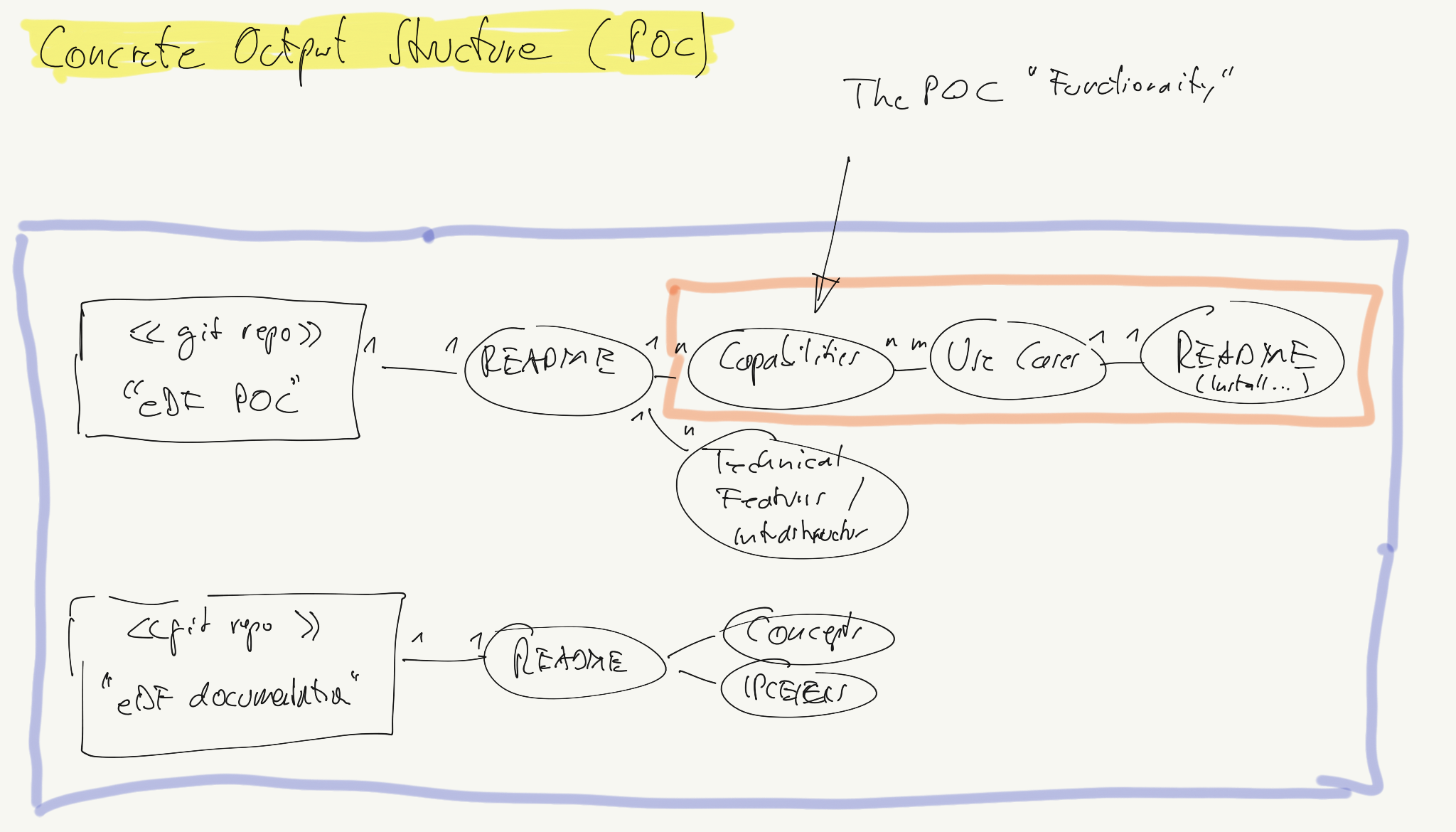
recommended: multi-repo over monorepo
git init –> always create as fast as possible a new repoThe following topics are optional and do not need an agreement at the moment:
Recommendation: at least ‘WiP’ would be good if the state is experimental
The following table lists an analysis of the status of the ‘Funcionality validation’ of the POC. Assumption: These functionalities should be the aforementioned capabilities.
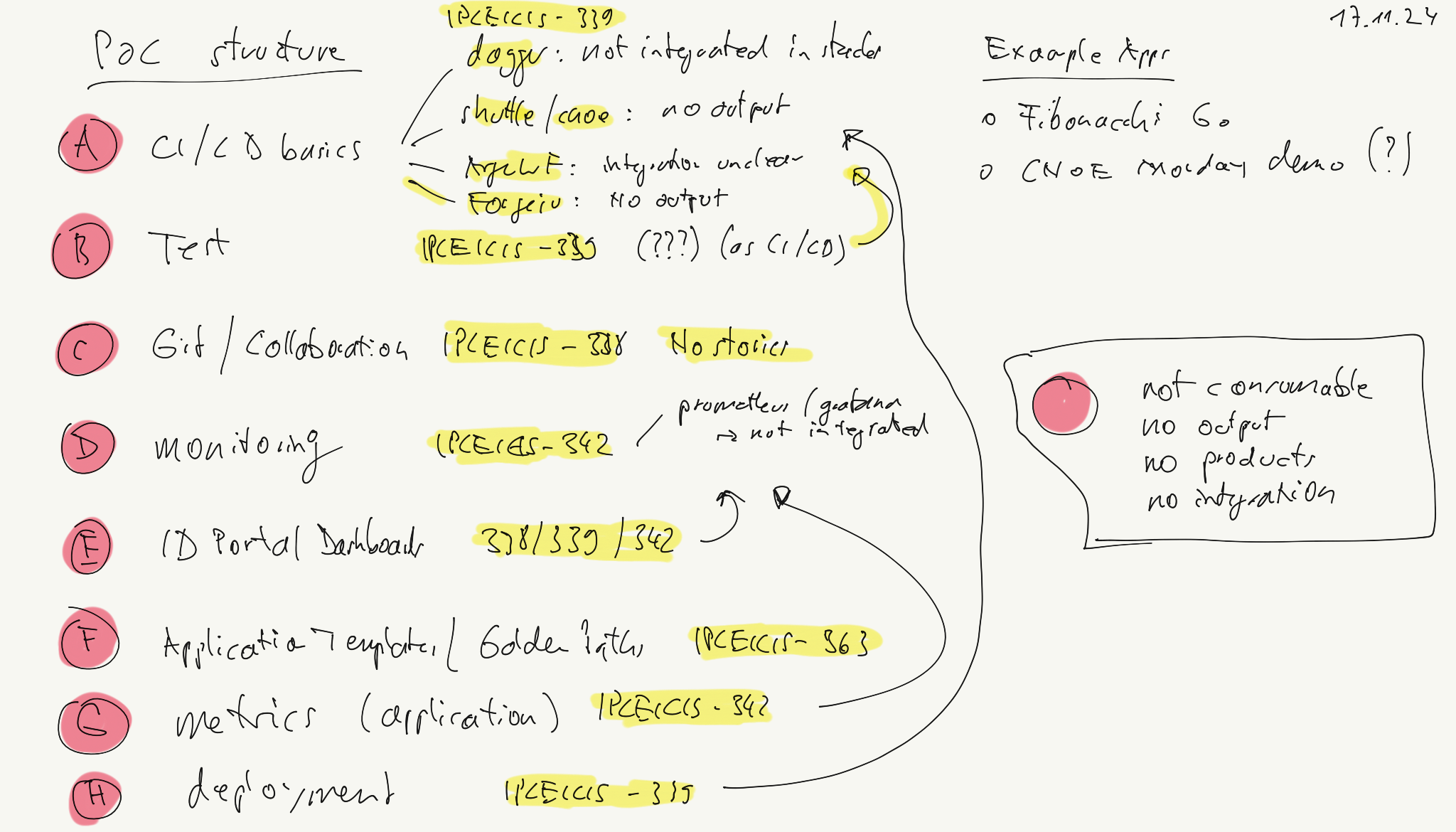
welche agilen vorgehensmodelle bzw. best practices gibt es in der software-entwicklung, wenn das product backlog noch nicht da ist. es gibt zwar eine produktvision und auch schon einen PoC, aber das Produkt ist sowohl technisch als auch nutzenseitig immer nocht nicht planbar in user stories. daher ist SCRUM nicht machbar. das team ist ca. 8 personen groß, und wir überlgen, einen meilenstein in den nächsten 8 wochen einfach durch tägliches ‘PDCA’ zu erstellen: ein morgendliches planning, dann in subgruppen ein erforschen, dann im Plenum wieder C (Check) zusammenführen/integrieren, und ein abschliessendes ‘A’ als Ergebnissicherung, Versionierierung, Dokumentation. Was hälst du von diesem Vorgehen, bzw. welches Risiken und Verbesserungsvorschläge hast du? Oder gibt es ein Standard-Vorgehen hierfür?
Dein beschriebenes Szenario – Vision und PoC vorhanden, aber kein ausformuliertes Product Backlog – ist typisch für eine frühe Explorations- oder Inceptionsphase in der Produktentwicklung. In dieser Phase ist klassisches Scrum tatsächlich oft zu starr, weil es eine gewisse Klarheit über Features und Stories voraussetzt. Das von euch überlegte Vorgehen klingt nach einer sehr pragmatischen und iterativen Methode, die im Kern gut zu den Lean-Startup-Prinzipien oder Design Thinking + Agile Engineering passt.
Positiv:
Risiken:
Exploration Backlog oder Hypothesenboard: Auch ohne klassisches Product Backlog könnt ihr mit einem Experiment-/Hypothesenboard (à la Lean Startup) arbeiten. Zum Beispiel:
Wöchentliche Zielsetzungen: Jeden Montag ein Weekly Planning mit klaren Zielen für die Woche (Outcome-fokussiert, nicht Task-fokussiert).
Integration mit Dual Track Agile: Das Vorgehen ähnelt dem Dual-Track-Modell: ein Discovery-Track (Erkunden, Validieren, Prototypisieren) läuft parallel zum späteren Delivery-Track (Releases, Sprints). Ihr seid noch voll im Discovery-Track.
Design Studio oder Spike-Zeitfenster: Strukturiert Zeit für z. B. 2-Tages-Design-Studios oder 1-Tages-Spikes – das erhöht die Qualität der Exploration.
Review/Share-Session freitags: Eine fixe wöchentliche Review-/Demo-Session (auch intern) erhöht die Disziplin und hilft beim „Check“-Teil im PDCA.
Fazit:
Euer PDCA-Zyklus ist ein solider, pragmatischer Einstieg in eine unsichere, vorstrukturierte Produktphase. Mit ein paar Ergänzungen (Exploration Backlog, feste Review-Elemente, Hypothesenstruktur) könnt ihr daraus ein effektives Discovery-Vorgehen machen, das den Übergang zu einem klassischen agilen Framework (z. B. Scrum) vorbereitet.
Möchtest du eine konkrete Vorlage für ein Exploration Backlog oder Hypothesenboard für euer Team?
ok, du findest vor allem Tages-Zyklen zu kurz. Ich möchte noch ergänzen, dass wir eine Architektur haben. Das klingt vielleicht paradox, aber es ist tatsächlich so, dass wir das Software-syewtm bereits designed haben, und die Komponenten auch bereits kennen, aber jetzt vor allem die Wege des automatischen Deployments in eine Cloud und die Konfigurations- und Verwaltungsstrukturen unsrerer Software herausfinden müssen. Das ist da, was sich gerade nicht weiter planen lässt. Kannst du mit diesen Ergänzungen dein Feedbach nochmal schärfen?
Danke für die Ergänzung – das ändert die Ausgangslage entscheidend und erlaubt eine deutlich präzisere Einordnung.
Bei Infrastruktur-, Deployment- oder Konfigurationsfragen entstehen oft tiefe „Spikes“ (z. B. CI/CD-Pipeline aufsetzen, Helm-Chart modellieren, Secrets Handling evaluieren). Diese brauchen oft mehr als einen Tag bis zum „Check“, weil Abhängigkeiten (z. B. Rechte, Cloud-Zugänge, Testumgebungen) entstehen. Ein 2- bis 3-Tages-Rhythmus mit klaren Zwischenzielen wäre realistischer, ergänzt um:
Ihr steckt im Übergang von Architektur zu einem Infrastructure as Code + Plattform Enablement Track. Das bedeutet:
Das spricht für ein Infrastructure Kanban Board, keine Sprints.
| Modell / Methode | Warum es jetzt passt |
|---|---|
| Kanban für technische Tasks | Flexible Work-in-Progress-Kontrolle, ideal für Exploration. |
| Spikes (aus XP) | Timeboxed Exploration zu offenen Fragen (z. B. Helm, Secrets). |
| Enabler Epics (SAFe) | Deployment- und Ops-Fragen formal als “Enabler” fassen. |
| Team Topologies – Platform Team Light | Ihr agiert gerade wie ein internes Plattform-Team. |
| Weekly DevOps Review | Alle 5–7 Tage Stand der Automatisierung/Doku/Strukturen. |
| ADRs & Living Docs | Architectural Decision Records für Deployment-/Ops-Entscheidungen. |
Ihr seid im “technisch operativen Enablement” eures Systems, nicht im Produkt-Delivery. Das rechtfertigt:
SCRUM ist hier fehl am Platz, aber euer Ansatz ist sehr nahe an einer modernen DevOps-orientierten Arbeitsweise, die z. B. von Platform Engineering Teams eingesetzt wird.
Möchtest du ein Beispiel für ein solches Kanban-Board mit passenden Task-Typen und Zielstruktur?
ja, gerne!
Hier ist ein konkretes Beispiel für ein Kanban-Board, das speziell auf eure Situation als „Platform/Enablement“-Team mit einem vorhandenen Architekturbild, aber offenem Deployment- und Betriebsdesign zugeschnitten ist.
Diese formuliert ihr am besten als Capabilities – Fähigkeiten, die das System nachher haben soll:
| Capability ID | Zielbeschreibung |
|---|---|
| C1 | Anwendung kann automatisiert in Cloudumgebung X deployed werden (inkl. Secrets Mgmt) |
| C2 | Konfiguration des Systems ist externisiert und dokumentiert (ENV, YAML, o. ä.) |
| C3 | Monitoring- und Logging-Infrastruktur ist einsatzbereit und dokumentiert |
| C4 | Dev- und Test-Umgebungen sind klar getrennt und automatisch provisionierbar |
| C5 | Alle Plattformentscheidungen (z. B. Helm vs. Kustomize) sind versioniert und begründet |
Diese Capabilities bilden Spalten oder Swimlanes im Board (wenn euer Tool das unterstützt, z. B. GitHub Projects, Jira oder Trello mit Labels).
| Spalte | Zweck |
|---|---|
| 🔍 Backlog | Ideen, Hypothesen, Tasks – priorisiert nach Capabilities |
| 🧪 In Exploration | Aktive Spikes, Proofs, technische Evaluierungen |
| 🛠️ In Progress | Umsetzung mit konkretem Ziel |
| ✅ Review / Check | Funktionsprüfung, internes Review |
| 📦 Done | Abgeschlossen, dokumentiert, ggf. in Repo |
| Symbol / Label | Typ | Beispiel |
|---|---|---|
| 🧪 Spike | Technische Untersuchung | „Untersuche ArgoCD vs. Flux für GitOps Deployment“ |
| 📦 Infra | Infrastruktur | „Provisioniere dev/test/stage in GCP mit Terraform“ |
| 🔐 Secrets | Sicherheitsrelevante Aufgabe | „Design für Secret-Handling mit Sealed Secrets“ |
| 📓 Docs | Dokumentation | „README für Developer Setup schreiben“ |
| 🧰 Tooling | CI/CD, Pipelines, Linter | „GitHub Action für Build & Deploy schreiben“ |
| 🔁 Entscheidung | Architekturentscheidung | „ADR: Helm vs. Kustomize für Service Deployment“ |
| Task | Typ | Status |
|---|---|---|
| Write GitHub Action for Docker image push | 🧰 Tooling | 🛠️ In Progress |
| Evaluate ArgoCD vs. Flux | 🧪 Spike | ✅ Review |
| Create Helm Chart for Service A | 📦 Infra | 🔍 Backlog |
| Create ADR: Deployment-Toolentscheidung | 🔁 Entscheidung | 🔍 Backlog |
| Add deployment doc in Wiki | 📓 Docs | 🔍 Backlog |
Wenn du magst, kann ich dir ein Beispiel-Board als Markdown-Vorlage oder als CSV-Datei zum Import in Trello, GitHub Projects, Jira etc. machen. Wäre das hilfreich?
kannst du noch etwas mehr zu ‘LivingDocs’ sagen?
Ja, gerne! “Living Docs” (bzw. Living Documentation) ist ein Konzept aus der agilen Softwareentwicklung und DevOps, das sich auf aktuelle, direkt aus dem System oder aus dem Arbeitsprozess generierte Dokumentation bezieht. Ziel ist es, dass die Dokumentation nicht veraltet, sondern so eng mit Code und Systemzustand gekoppelt ist, dass sie sich (teilweise) selbst aktualisiert oder sich mit dem Entwicklungsprozess mitbewegt.
| Merkmal | Beschreibung |
|---|---|
| 🔄 Automatisch erzeugt oder aktualisiert | Generiert aus Code, Tests, Pipelines, ADRs oder Deployments |
| 📌 Versionskontrolliert | Im Git abgelegt, gemeinsam mit dem Code gepflegt |
| 🧑💻 Entwicklernah | Entwickelt sich mit dem Code weiter – keine Trennung zwischen “Docs” und Dev |
| 📈 Änderbar & nachvollziehbar | Jede Änderung an Code/Doku hat einen Commit & Kontext |
| 📚 Mehrwert für alle Beteiligten | Richtet sich an Devs, Ops, PMs oder andere Teams – nicht nur “für später” |
| Typ | Beschreibung & Tools |
|---|---|
| Architecture Decision Records (ADRs) | Markdown-Dateien im Repo (z. B. docs/adr/001-helm-vs-kustomize.md) |
| Code-Doku aus Source | Mit Tools wie JSDoc, TypeDoc, Sphinx, Doxygen, etc. |
| API-Doku | Automatisch aus Code oder OpenAPI (Swagger) generiert |
| Test-Doku (z. B. BDD) | z. B. Gherkin-Style: Given/When/Then-Spezifikationen als Dokumentation |
| Monitoring & Deployment-Status | z. B. Dashboards mit Infrastructure-Doku (Grafana, Backstage, Argo UI) |
| DevDocs im Repo | z. B. README.md, CONTRIBUTING.md, how-to/, docs/, adr/ |
| Playbooks / Runbooks | Schritt-für-Schritt-Anleitungen für Betrieb oder Störungen |
system-overview.md.| Zweck | Tools (Beispiele) |
|---|---|
| ADRs | adr-tools, einfaches Markdown |
| Markdown-Doku | MkDocs, Docusaurus, GitBook |
| API-Doku | Swagger/OpenAPI, Redocly |
| Infrastruktur-Doku | Backstage (Spotify), Terraform-docs |
| Doku-Automatisierung | GitHub Actions, pre-commit Hooks, CI-Checks |
“Dokumentation ist kein Nachtrag, sondern ein asynchrones Gespräch mit deinem zukünftigen Ich – oder dem nächsten Teammitglied.”
Gerade in eurem Kontext (technisches Enablement, Deployment, Betrieb) ist das entscheidungsorientierte, leichtgewichtige Festhalten von Kontext Gold wert. ADRs und docs/runbooks/-Verzeichnisse sind ein idealer Startpunkt.
Möchtest du eine Vorlage für ein ADR oder ein Beispielverzeichnis für eine sinnvolle Living-Docs-Struktur im Repo?
{kind=link}
{kind=link}